Initial publication.
This commit is contained in:
commit
6d40170c78
49 changed files with 13633 additions and 0 deletions
2
.gitignore
vendored
Normal file
2
.gitignore
vendored
Normal file
|
|
@ -0,0 +1,2 @@
|
|||
_bringrss/*
|
||||
myscripts/*
|
||||
12
CONTACT.md
Normal file
12
CONTACT.md
Normal file
|
|
@ -0,0 +1,12 @@
|
|||
Contact
|
||||
=======
|
||||
|
||||
Please do not open pull requests without talking to me first. For serious issues and bugs, open a GitHub issue. If you just have a question, please send an email to `contact@voussoir.net`. For other contact options, see [voussoir.net/#contact](https://voussoir.net/#contact).
|
||||
|
||||
I also mirror my work to other git services:
|
||||
|
||||
- https://github.com/voussoir
|
||||
|
||||
- https://gitlab.com/voussoir
|
||||
|
||||
- https://codeberg.org/voussoir
|
||||
29
LICENSE.txt
Normal file
29
LICENSE.txt
Normal file
|
|
@ -0,0 +1,29 @@
|
|||
BSD 3-Clause License
|
||||
|
||||
Copyright (c) 2022, Ethan Dalool aka voussoir
|
||||
All rights reserved.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without
|
||||
modification, are permitted provided that the following conditions are met:
|
||||
|
||||
1. Redistributions of source code must retain the above copyright notice, this
|
||||
list of conditions and the following disclaimer.
|
||||
|
||||
2. Redistributions in binary form must reproduce the above copyright notice,
|
||||
this list of conditions and the following disclaimer in the documentation
|
||||
and/or other materials provided with the distribution.
|
||||
|
||||
3. Neither the name of the copyright holder nor the names of its
|
||||
contributors may be used to endorse or promote products derived from
|
||||
this software without specific prior written permission.
|
||||
|
||||
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
||||
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
||||
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
||||
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
||||
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
||||
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
||||
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
||||
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
||||
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
148
README.md
Normal file
148
README.md
Normal file
|
|
@ -0,0 +1,148 @@
|
|||
BringRSS
|
||||
========
|
||||
|
||||
It brings you the news.
|
||||
|
||||
Live demo: https://bringrss.voussoir.net
|
||||
|
||||
## What am I looking at
|
||||
|
||||
BringRSS is an RSS client / newsreader made with Python, SQLite3, and Flask. Its main features are:
|
||||
|
||||
- Automatic feed refresh with separate intervals per feed.
|
||||
- Feeds arranged in hierarchical folders.
|
||||
- Filters for categorizing or removing news based on your criteria.
|
||||
- Sends news objects to your own Python scripts for arbitrary post-processing, emailing, downloading, etc.
|
||||
- Embeds videos from YouTube feeds.
|
||||
- News text is filtered by [DOMPurify](https://github.com/cure53/DOMPurify) before display.
|
||||
- Supports multiple enclosures.
|
||||
|
||||
Because BringRSS runs a webserver, you can access it from every device in your house via your computer's LAN IP. BringRSS provides no login or authentication, but if you have a reverse proxy handle that for you, you could run BringRSS on an internet-connected machine and access your feeds anywhere.
|
||||
|
||||
## Screenshots
|
||||
|
||||
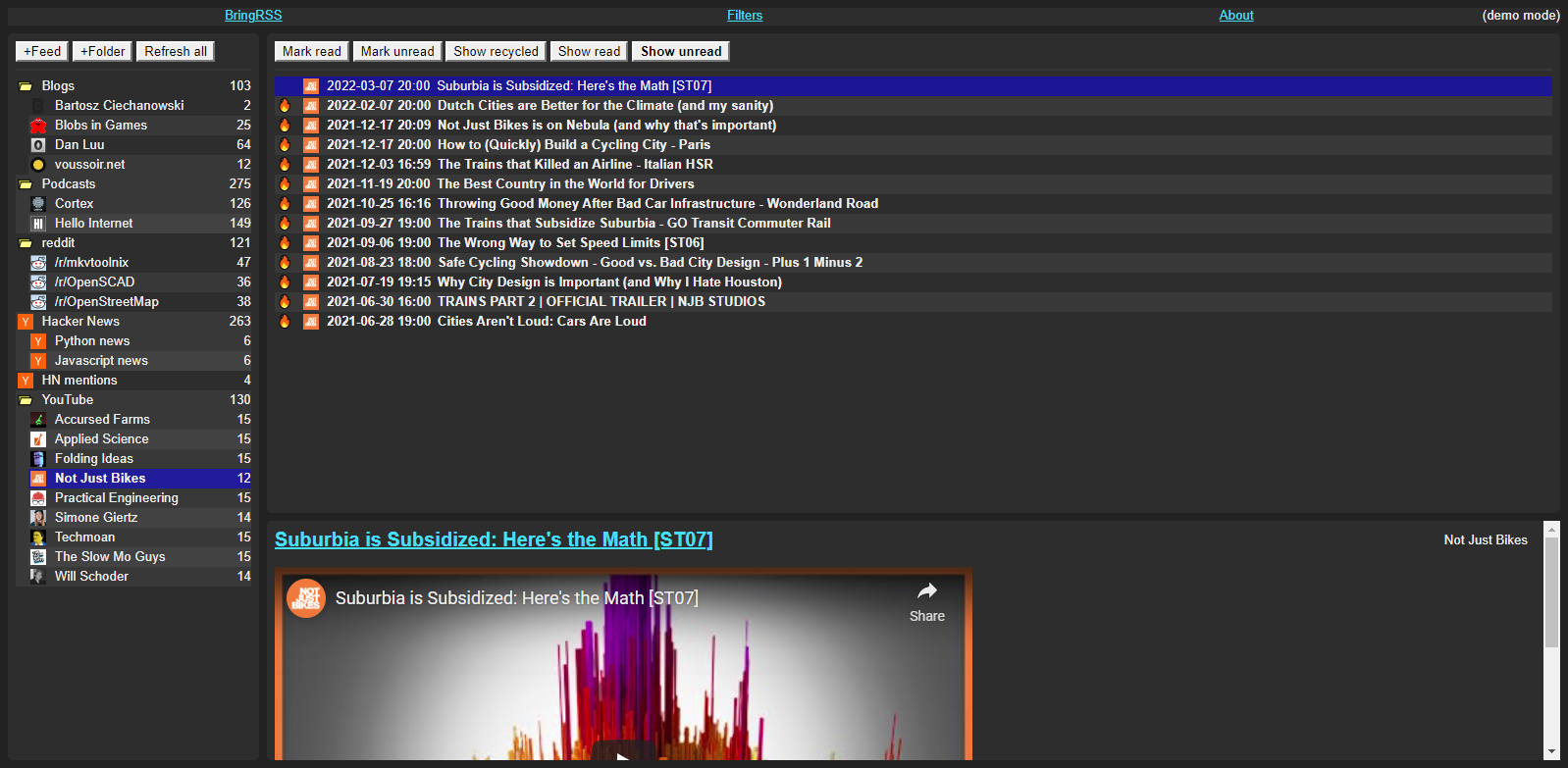
|
||||
|
||||
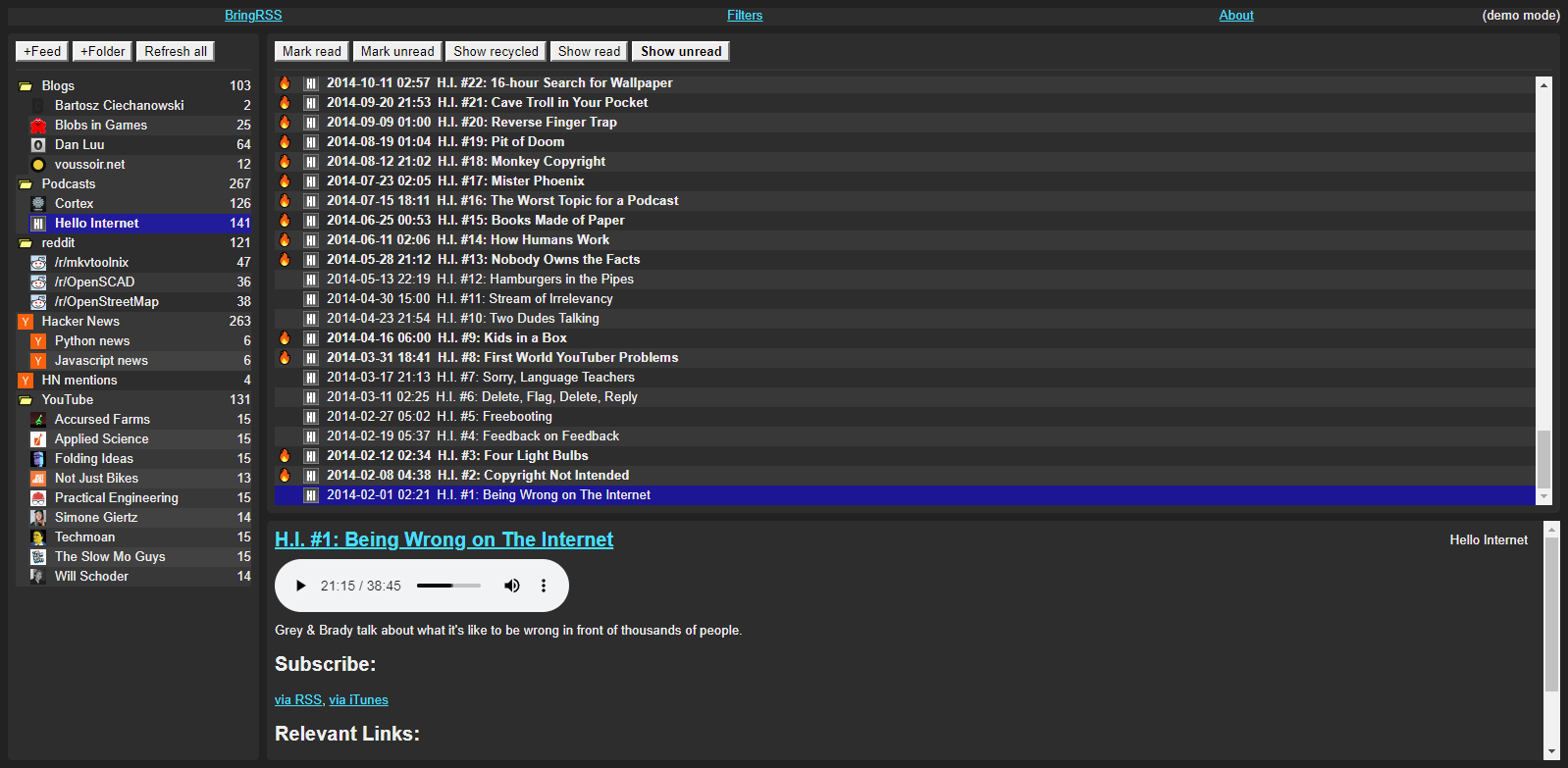
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
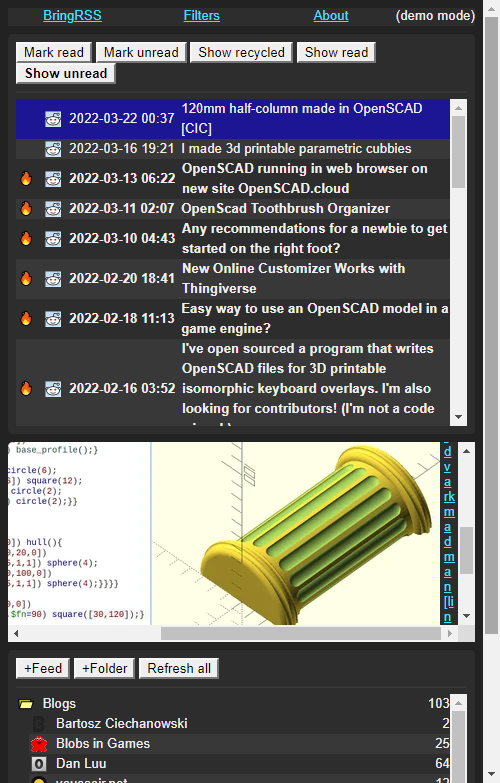
|
||||
|
||||
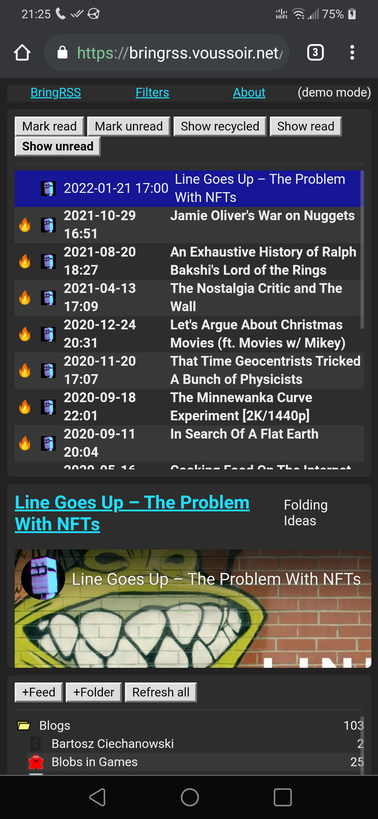
|
||||
|
||||
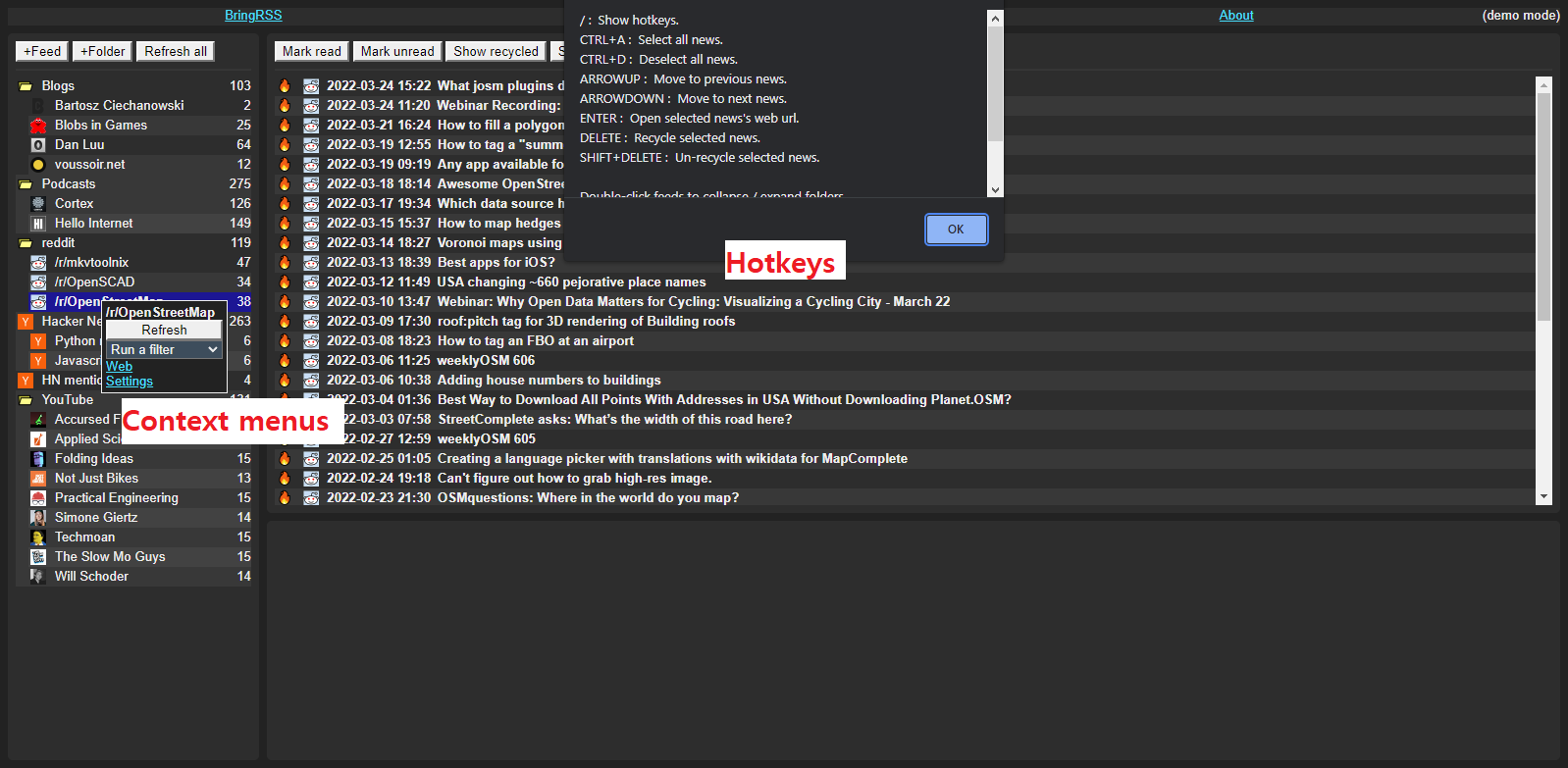
|
||||
|
||||
## Setting up
|
||||
|
||||
As you'll see below, BringRSS has a core backend package and separate frontends that use it. These frontend applications will use `import bringrss` to access the backend code. Therefore, the `bringrss` package needs to be in the right place for Python to find it for `import`.
|
||||
|
||||
1. Run `pip install -r requirements.txt --upgrade` after reading the file and deciding you are ok with the dependencies.
|
||||
|
||||
2. Make a new folder somewhere on your computer, and add this folder to your `PYTHONPATH` environment variable. For example, I might use `D:\pythonpath` or `~/pythonpath`. Close and re-open your Command Prompt / Terminal so it reloads the environment variables.
|
||||
|
||||
3. Add a symlink to the bringrss folder into that folder:
|
||||
|
||||
The repository you are looking at now is `D:\Git\BringRSS` or `~/Git/BringRSS`. You can see the folder called `bringrss`.
|
||||
|
||||
Windows: `mklink /d fakepath realpath`
|
||||
for example `mklink /d "D:\pythonpath\bringrss" "D:\Git\BringRSS\bringrss"`
|
||||
|
||||
Linux: `ln --symbolic realpath fakepath`
|
||||
for example `ln --symbolic "~/Git/BringRSS/bringrss" "~/pythonpath/bringrss"`
|
||||
|
||||
4. Run `python -c "import bringrss; print(bringrss)"`. You should see the module print successfully.
|
||||
|
||||
## Running BringRSS CLI
|
||||
|
||||
BringRSS offers a commandline interface so you can use cronjobs to refresh your feeds. More commands may be added in the future.
|
||||
|
||||
1. `cd` to the folder where you'd like to create the BringRSS database.
|
||||
|
||||
2. Run `python frontends/bringrss_cli.py --help` to learn about the available commands.
|
||||
|
||||
3. Run `python frontends/bringrss_cli.py init` to create a database in the current directory.
|
||||
|
||||
Note: Do not `cd` into the frontends folder. Stay in the folder that contains your `_bringrss` database and specify the full path of the frontend launcher. For example:
|
||||
|
||||
Windows:
|
||||
D:\somewhere> python D:\Git\BringRSS\frontends\bringrss_cli.py
|
||||
|
||||
Linux:
|
||||
/somewhere $ python /Git/BringRSS/frontends/bringrss_cli.py
|
||||
|
||||
It is expected that you create a shortcut file or launch script so you don't have to type the whole filepath every time. For example, I have a `bringcli.lnk` on my PATH with `target=D:\Git\BringRSS\frontends\bringrss_cli.py`.
|
||||
|
||||
## Running BringRSS Flask locally
|
||||
|
||||
1. Run `python frontends/bringrss_flask/bringrss_flask_dev.py --help` to learn the available options.
|
||||
|
||||
2. Run `python frontends/bringrss_flask/bringrss_flask_dev.py [port]` to launch the flask server. If this is your first time running it, you can add `--init` to create a new database in the current directory. Port defaults to 27464 if not provided.
|
||||
|
||||
3. Open your web browser to `localhost:<port>`.
|
||||
|
||||
Note: Do not `cd` into the frontends folder. Stay in the folder that contains your `_bringrss` database and specify the full path of the frontend launcher. For example:
|
||||
|
||||
Windows:
|
||||
D:\somewhere> python D:\Git\BringRSS\frontends\bringrss_flask\bringrss_flask_dev.py 5001
|
||||
|
||||
Linux:
|
||||
/somewhere $ python /Git/BringRSS/frontends/bringrss_flask/bringrss_flask_dev.py 5001
|
||||
|
||||
Add `--help` to learn the arguments.
|
||||
|
||||
It is expected that you create a shortcut file or launch script so you don't have to type the whole filepath every time. For example, I have a `bringflask.lnk` on my PATH with `target=D:\Git\BringRSS\frontends\bringrss_flask\bringrss_flask_dev.py`.
|
||||
|
||||
## Running BringRSS Flask with Gunicorn
|
||||
|
||||
BringRSS provides no authentication whatsoever, so you probably shouldn't deploy it publicly unless your proxy server does authentication for you. However, I will tell you that for the purposes of running the demo site, I am using a script like this:
|
||||
|
||||
export BRINGRSS_DEMO_MODE=1
|
||||
~/cmd/python ~/cmd/gunicorn_py bringrss_flask_prod:site --bind "0.0.0.0:PORTNUMBER" --worker-class gevent --access-logfile "-" --access-logformat "%(h)s | %(t)s | %(r)s | %(s)s %(b)s"
|
||||
|
||||
## Running BringRSS REPL
|
||||
|
||||
The REPL is a great way to test a quick idea and learn the data model.
|
||||
|
||||
1. Use `bringrss_cli init` to create the database in the desired directory.
|
||||
|
||||
2. Run `python frontends/bringrss_repl.py` to launch the Python interpreter with the BringDB pre-loaded into a variable called `B`. Try things like `B.get_feed` or `B.get_newss`.
|
||||
|
||||
Note: Do not `cd` into the frontends folder. Stay in the folder that contains your `_bringrss` database and specify the full path of the frontend launcher. For example:
|
||||
|
||||
Windows:
|
||||
D:\somewhere> python D:\Git\BringRSS\frontends\bringrss_repl.py
|
||||
|
||||
Linux:
|
||||
/somewhere $ python /Git/BringRSS/frontends/bringrss_repl.py
|
||||
|
||||
It is expected that you create a shortcut file or launch script so you don't have to type the whole filepath every time. For example, I have a `bringrepl.lnk` on my PATH with `target=D:\Git\BringRSS\frontends\bringrss_repl.py`.
|
||||
|
||||
## Help wanted: javascript perf & layout thrashing
|
||||
|
||||
I think there is room for improvement in [root.html](https://github.com/voussoir/bringrss/blob/master/frontends/bringrss_flask/templates/root.html)'s javascript. When reading a feed with a few thousand news items, the UI starts to get slow at every interaction:
|
||||
|
||||
- After clicking on a news, it takes a few ms before it turns selected.
|
||||
- The newsreader takes a few ms to populate with the title even though it's pulled from the news's DOM, not the network.
|
||||
- After receiving the news list from the server, news are inserted into the dom in batches, and each batch causes the UI to stutter if you are also trying to scroll or click on things.
|
||||
|
||||
If you have any tips for improving the performance and responsiveness of the UI click handlers and reducing the amount of reflow / layout caused by the loading of news items or changing their class (selecting, reading, recycling), I would appreciate you getting in touch at contact@voussoir.net or opening an issue. Please don't open a pull request without talking to me first.
|
||||
|
||||
I am aware of virtual scrolling techniques where DOM rows don't actually exist until you scroll to where they would be, but this has the drawback of breaking ctrl+f and also it is hard to precompute the scroll height since news have variable length titles. I would prefer simple fixes like adding CSS rules that help the layout engine make better reflow decisions.
|
||||
|
||||
## To do list
|
||||
|
||||
- Maybe we could add a very basic password system to facilitate running an internet-connected instance. No user profiles, just a single password to access the whole system. I did this with [simpleserver](https://github.com/voussoir/else/blob/master/SimpleServer/simpleserver.py).
|
||||
- "Fill in the gaps" feature. Many websites have feeds that don't reach back all the way to their first post. When discovering a new blog or podcast, catching up on their prior work requires manual bookmarking outside of your newsreader. It would be nice to dump a list of article URLs into BringRSS and have it generate news objects as if they really came from the feed. Basic information like url, title, and fetched page text would be good enough; auto-detecting media as enclosures would be better. Other attributes don't need to be comprehensive. Then you could have everything in your newsreader.
|
||||
|
||||
## Mirrors
|
||||
|
||||
https://github.com/voussoir/bringrss
|
||||
|
||||
https://gitlab.com/voussoir/bringrss
|
||||
|
||||
https://codeberg.com/voussoir/bringrss
|
||||
5
bringrss/__init__.py
Normal file
5
bringrss/__init__.py
Normal file
|
|
@ -0,0 +1,5 @@
|
|||
from . import bringdb
|
||||
from . import constants
|
||||
from . import exceptions
|
||||
from . import helpers
|
||||
from . import objects
|
||||
722
bringrss/bringdb.py
Normal file
722
bringrss/bringdb.py
Normal file
|
|
@ -0,0 +1,722 @@
|
|||
import bs4
|
||||
import random
|
||||
import sqlite3
|
||||
import typing
|
||||
|
||||
from . import constants
|
||||
from . import exceptions
|
||||
from . import helpers
|
||||
from . import objects
|
||||
|
||||
from voussoirkit import cacheclass
|
||||
from voussoirkit import pathclass
|
||||
from voussoirkit import sentinel
|
||||
from voussoirkit import sqlhelpers
|
||||
from voussoirkit import vlogging
|
||||
from voussoirkit import worms
|
||||
|
||||
log = vlogging.get_logger(__name__)
|
||||
|
||||
RNG = random.SystemRandom()
|
||||
|
||||
####################################################################################################
|
||||
|
||||
class BDBFeedMixin:
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
@worms.transaction
|
||||
def add_feed(
|
||||
self,
|
||||
*,
|
||||
autorefresh_interval=86400,
|
||||
description=None,
|
||||
icon=None,
|
||||
isolate_guids=False,
|
||||
parent=None,
|
||||
refresh_with_others=True,
|
||||
rss_url=None,
|
||||
title=None,
|
||||
web_url=None,
|
||||
ui_order_rank=None,
|
||||
):
|
||||
if parent is None:
|
||||
parent_id = None
|
||||
else:
|
||||
if not isinstance(parent, objects.Feed):
|
||||
raise TypeError(parent)
|
||||
parent.assert_not_deleted()
|
||||
parent_id = parent.id
|
||||
|
||||
autorefresh_interval = objects.Feed.normalize_autorefresh_interval(autorefresh_interval)
|
||||
refresh_with_others = objects.Feed.normalize_refresh_with_others(refresh_with_others)
|
||||
rss_url = objects.Feed.normalize_rss_url(rss_url)
|
||||
web_url = objects.Feed.normalize_web_url(web_url)
|
||||
title = objects.Feed.normalize_title(title)
|
||||
description = objects.Feed.normalize_description(description)
|
||||
icon = objects.Feed.normalize_icon(icon)
|
||||
isolate_guids = objects.Feed.normalize_isolate_guids(isolate_guids)
|
||||
if ui_order_rank is None:
|
||||
ui_order_rank = self.get_last_ui_order_rank() + 1
|
||||
else:
|
||||
ui_order_rank = objects.Feed.normalize_ui_order_rank(ui_order_rank)
|
||||
|
||||
data = {
|
||||
'id': self.generate_id(objects.Feed),
|
||||
'parent_id': parent_id,
|
||||
'rss_url': rss_url,
|
||||
'web_url': web_url,
|
||||
'title': title,
|
||||
'description': description,
|
||||
'created': helpers.now(),
|
||||
'refresh_with_others': refresh_with_others,
|
||||
'last_refresh': 0,
|
||||
'last_refresh_attempt': 0,
|
||||
'last_refresh_error': None,
|
||||
'autorefresh_interval': autorefresh_interval,
|
||||
'http_headers': None,
|
||||
'isolate_guids': isolate_guids,
|
||||
'icon': icon,
|
||||
'ui_order_rank': ui_order_rank,
|
||||
}
|
||||
self.insert(table=objects.Feed, data=data)
|
||||
feed = self.get_cached_instance(objects.Feed, data)
|
||||
return feed
|
||||
|
||||
def get_bulk_unread_counts(self):
|
||||
'''
|
||||
Instead of calling feed.get_unread_count() on many separate feed objects
|
||||
and performing lots of duplicate work, you can call here and get them
|
||||
all at once with much less database access. I brought my /feeds.json
|
||||
down from 160ms to 6ms by using this.
|
||||
|
||||
Missing keys means 0 unread.
|
||||
'''
|
||||
# Even though we have api functions for all of this, I want to squeeze
|
||||
# out the perf. This function is meant to be used in situations where
|
||||
# speed matters more than code beauty.
|
||||
feeds = {feed.id: feed for feed in self.get_feeds()}
|
||||
childs = {}
|
||||
for feed in feeds.values():
|
||||
if feed.parent_id:
|
||||
childs.setdefault(feed.parent_id, []).append(feed)
|
||||
roots = [feed for feed in feeds.values() if not feed.parent_id]
|
||||
|
||||
query = '''
|
||||
SELECT feed_id, COUNT(rowid)
|
||||
FROM news
|
||||
WHERE recycled == 0 AND read == 0
|
||||
GROUP BY feed_id
|
||||
'''
|
||||
counts = {feeds[feed_id]: count for (feed_id, count) in self.select(query)}
|
||||
|
||||
def recursive_update(feed):
|
||||
counts.setdefault(feed, 0)
|
||||
children = childs.get(feed.id, None)
|
||||
if children:
|
||||
counts[feed] += sum(recursive_update(child) for child in children)
|
||||
pass
|
||||
return counts[feed]
|
||||
|
||||
for root in roots:
|
||||
recursive_update(root)
|
||||
|
||||
return counts
|
||||
|
||||
def get_feed(self, id) -> objects.Feed:
|
||||
return self.get_object_by_id(objects.Feed, id)
|
||||
|
||||
def get_feed_count(self) -> int:
|
||||
return self.select_one_value('SELECT COUNT(id) FROM feeds')
|
||||
|
||||
def get_feeds(self) -> typing.Iterable[objects.Feed]:
|
||||
query = 'SELECT * FROM feeds ORDER BY ui_order_rank ASC'
|
||||
return self.get_objects_by_sql(objects.Feed, query)
|
||||
|
||||
def get_feeds_by_id(self, ids) -> typing.Iterable[objects.Feed]:
|
||||
return self.get_objects_by_id(objects.Feed, ids)
|
||||
|
||||
def get_feeds_by_sql(self, query, bindings=None) -> typing.Iterable[objects.Feed]:
|
||||
return self.get_objects_by_sql(objects.Feed, query, bindings)
|
||||
|
||||
def get_last_ui_order_rank(self) -> int:
|
||||
query = 'SELECT ui_order_rank FROM feeds ORDER BY ui_order_rank DESC LIMIT 1'
|
||||
rank = self.select_one_value(query)
|
||||
if rank is None:
|
||||
return 0
|
||||
return rank
|
||||
|
||||
def get_root_feeds(self) -> typing.Iterable[objects.Feed]:
|
||||
query = 'SELECT * FROM feeds WHERE parent_id IS NULL ORDER BY ui_order_rank ASC'
|
||||
return self.get_objects_by_sql(objects.Feed, query)
|
||||
|
||||
@worms.transaction
|
||||
def reassign_ui_order_ranks(self):
|
||||
feeds = list(self.get_root_feeds())
|
||||
rank = 1
|
||||
for feed in feeds:
|
||||
for descendant in feed.walk_children():
|
||||
descendant.set_ui_order_rank(rank)
|
||||
rank += 1
|
||||
|
||||
####################################################################################################
|
||||
|
||||
class BDBFilterMixin:
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
@worms.transaction
|
||||
def add_filter(self, name, conditions, actions):
|
||||
name = objects.Filter.normalize_name(name)
|
||||
conditions = objects.Filter.normalize_conditions(conditions)
|
||||
actions = objects.Filter.normalize_actions(actions)
|
||||
objects.Filter._jank_validate_move_to_feed(bringdb=self, actions=actions)
|
||||
|
||||
data = {
|
||||
'id': self.generate_id(objects.Filter),
|
||||
'name': name,
|
||||
'created': helpers.now(),
|
||||
'conditions': conditions,
|
||||
'actions': actions,
|
||||
}
|
||||
self.insert(table=objects.Filter, data=data)
|
||||
filt = self.get_cached_instance(objects.Filter, data)
|
||||
return filt
|
||||
|
||||
def get_filter(self, id) -> objects.Filter:
|
||||
return self.get_object_by_id(objects.Filter, id)
|
||||
|
||||
def get_filter_count(self) -> int:
|
||||
return self.select_one_value('SELECT COUNT(id) FROM filters')
|
||||
|
||||
def get_filters(self) -> typing.Iterable[objects.Filter]:
|
||||
return self.get_objects(objects.Filter)
|
||||
|
||||
def get_filters_by_id(self, ids) -> typing.Iterable[objects.Filter]:
|
||||
return self.get_objects_by_id(objects.Filter, ids)
|
||||
|
||||
def get_filters_by_sql(self, query, bindings=None) -> typing.Iterable[objects.Filter]:
|
||||
return self.get_objects_by_sql(objects.Filter, query, bindings)
|
||||
|
||||
@worms.transaction
|
||||
def process_news_through_filters(self, news):
|
||||
def prepare_filters(feed):
|
||||
filters = []
|
||||
for ancestor in feed.walk_parents(yield_self=True):
|
||||
filters.extend(ancestor.get_filters())
|
||||
return filters
|
||||
|
||||
feed = news.feed
|
||||
original_feed = feed
|
||||
filters = prepare_filters(feed)
|
||||
status = objects.Filter.THEN_CONTINUE_FILTERS
|
||||
too_many_switches = 20
|
||||
|
||||
while feed and filters and status is objects.Filter.THEN_CONTINUE_FILTERS:
|
||||
filt = filters.pop(0)
|
||||
status = filt.process_news(news)
|
||||
|
||||
switched_feed = news.feed
|
||||
if switched_feed == feed:
|
||||
continue
|
||||
|
||||
feed = switched_feed
|
||||
filters = prepare_filters(feed)
|
||||
|
||||
too_many_switches -= 1
|
||||
if too_many_switches > 0:
|
||||
continue
|
||||
raise Exception(f'{news} from {original_feed} got moved too many times. Something wrong?')
|
||||
|
||||
####################################################################################################
|
||||
|
||||
class BDBNewsMixin:
|
||||
DUPLICATE_BAIL = sentinel.Sentinel('duplicate bail')
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
@worms.transaction
|
||||
def add_news(
|
||||
self,
|
||||
*,
|
||||
authors,
|
||||
comments_url,
|
||||
enclosures,
|
||||
feed,
|
||||
published,
|
||||
rss_guid,
|
||||
text,
|
||||
title,
|
||||
updated,
|
||||
web_url,
|
||||
):
|
||||
if not isinstance(feed, objects.Feed):
|
||||
raise TypeError(feed)
|
||||
feed.assert_not_deleted()
|
||||
|
||||
rss_guid = objects.News.normalize_rss_guid(rss_guid)
|
||||
if feed.isolate_guids:
|
||||
rss_guid = f'_isolate_{feed.id}_{rss_guid}'
|
||||
|
||||
published = objects.News.normalize_published(published)
|
||||
updated = objects.News.normalize_updated(updated)
|
||||
title = objects.News.normalize_title(title)
|
||||
text = objects.News.normalize_text(text)
|
||||
web_url = objects.News.normalize_web_url(web_url)
|
||||
comments_url = objects.News.normalize_comments_url(comments_url)
|
||||
authors = objects.News.normalize_authors_json(authors)
|
||||
enclosures = objects.News.normalize_enclosures_json(enclosures)
|
||||
|
||||
data = {
|
||||
'id': self.generate_id(objects.News),
|
||||
'feed_id': feed.id,
|
||||
'original_feed_id': feed.id,
|
||||
'rss_guid': rss_guid,
|
||||
'published': published,
|
||||
'updated': updated,
|
||||
'title': title,
|
||||
'text': text,
|
||||
'web_url': web_url,
|
||||
'comments_url': comments_url,
|
||||
'created': helpers.now(),
|
||||
'read': False,
|
||||
'recycled': False,
|
||||
'authors': authors,
|
||||
'enclosures': enclosures,
|
||||
}
|
||||
self.insert(table=objects.News, data=data)
|
||||
news = self.get_cached_instance(objects.News, data)
|
||||
return news
|
||||
|
||||
def get_news(self, id) -> objects.News:
|
||||
return self.get_object_by_id(objects.News, id)
|
||||
|
||||
def get_news_count(self) -> int:
|
||||
return self.select_one_value('SELECT COUNT(id) FROM news')
|
||||
|
||||
def get_newss(
|
||||
self,
|
||||
*,
|
||||
read=False,
|
||||
recycled=False,
|
||||
feed=None,
|
||||
) -> typing.Iterable[objects.News]:
|
||||
|
||||
if feed is not None and not isinstance(feed, objects.Feed):
|
||||
feed = self.get_feed(feed)
|
||||
|
||||
wheres = []
|
||||
bindings = []
|
||||
|
||||
if feed:
|
||||
feed_ids = [descendant.id for descendant in feed.walk_children()]
|
||||
wheres.append(f'feed_id IN {sqlhelpers.listify(feed_ids)}')
|
||||
|
||||
if recycled is True:
|
||||
wheres.append('recycled == 1')
|
||||
elif recycled is False:
|
||||
wheres.append('recycled == 0')
|
||||
|
||||
if read is True:
|
||||
wheres.append('read == 1')
|
||||
elif read is False:
|
||||
wheres.append('read == 0')
|
||||
if wheres:
|
||||
wheres = ' AND '.join(wheres)
|
||||
wheres = ' WHERE ' + wheres
|
||||
else:
|
||||
wheres = ''
|
||||
query = 'SELECT * FROM news' + wheres + ' ORDER BY published DESC'
|
||||
|
||||
rows = self.select(query, bindings)
|
||||
for row in rows:
|
||||
yield self.get_cached_instance(objects.News, row)
|
||||
|
||||
def get_newss_by_id(self, ids) -> typing.Iterable[objects.News]:
|
||||
return self.get_objects_by_id(objects.News, ids)
|
||||
|
||||
def get_newss_by_sql(self, query, bindings=None) -> typing.Iterable[objects.News]:
|
||||
return self.get_objects_by_sql(objects.News, query, bindings)
|
||||
|
||||
def _get_duplicate_news(self, feed, guid):
|
||||
if feed.isolate_guids:
|
||||
guid = f'_isolate_{feed.id}_{guid}'
|
||||
|
||||
match = self.select_one('SELECT * FROM news WHERE rss_guid == ?', [guid])
|
||||
if match is None:
|
||||
return None
|
||||
|
||||
return self.get_cached_instance(objects.News, match)
|
||||
|
||||
def _ingest_one_news_atom(self, entry, feed):
|
||||
rss_guid = entry.id
|
||||
|
||||
web_url = helpers.pick_web_url_atom(entry)
|
||||
|
||||
updated = entry.updated
|
||||
if updated is not None:
|
||||
updated = updated.text
|
||||
updated = helpers.dateutil_parse(updated)
|
||||
updated = updated.timestamp()
|
||||
|
||||
published = entry.published
|
||||
if published is not None:
|
||||
published = published.text
|
||||
published = helpers.dateutil_parse(published)
|
||||
published = published.timestamp()
|
||||
elif updated is not None:
|
||||
published = updated
|
||||
|
||||
title = entry.find('title')
|
||||
if title:
|
||||
title = title.text.strip()
|
||||
|
||||
if rss_guid:
|
||||
rss_guid = rss_guid.text.strip()
|
||||
elif web_url:
|
||||
rss_guid = web_url
|
||||
elif title:
|
||||
rss_guid = title
|
||||
elif published:
|
||||
rss_guid = published
|
||||
|
||||
if not rss_guid:
|
||||
raise exceptions.NoGUID(entry)
|
||||
|
||||
duplicate = self._get_duplicate_news(feed=feed, guid=rss_guid)
|
||||
if duplicate:
|
||||
log.loud('Skipping duplicate feed=%s, guid=%s', feed.id, rss_guid)
|
||||
return BDBNewsMixin.DUPLICATE_BAIL
|
||||
|
||||
text = entry.find('content')
|
||||
if text:
|
||||
text = text.text.strip()
|
||||
|
||||
comments_url = None
|
||||
|
||||
raw_authors = entry.find_all('author')
|
||||
authors = []
|
||||
for raw_author in raw_authors:
|
||||
author = {
|
||||
'name': raw_author.find('name'),
|
||||
'email': raw_author.find('email'),
|
||||
'uri': raw_author.find('uri'),
|
||||
}
|
||||
author = {key:(value.text if value else None) for (key, value) in author.items()}
|
||||
authors.append(author)
|
||||
|
||||
raw_enclosures = entry.find_all('link', {'rel': 'enclosure'})
|
||||
enclosures = []
|
||||
for raw_enclosure in raw_enclosures:
|
||||
enclosure = {
|
||||
'type': raw_enclosure.get('type', None),
|
||||
'url': raw_enclosure.get('href', None),
|
||||
'size': raw_enclosure.get('length', None),
|
||||
}
|
||||
if enclosure.get('size') is not None:
|
||||
enclosure['size'] = int(enclosure['size'])
|
||||
|
||||
enclosures.append(enclosure)
|
||||
|
||||
news = self.add_news(
|
||||
authors=authors,
|
||||
comments_url=comments_url,
|
||||
enclosures=enclosures,
|
||||
feed=feed,
|
||||
published=published,
|
||||
rss_guid=rss_guid,
|
||||
text=text,
|
||||
title=title,
|
||||
updated=updated,
|
||||
web_url=web_url,
|
||||
)
|
||||
return news
|
||||
|
||||
def _ingest_one_news_rss(self, item, feed):
|
||||
rss_guid = item.find('guid')
|
||||
|
||||
title = item.find('title')
|
||||
if title:
|
||||
title = title.text.strip()
|
||||
|
||||
text = item.find('description')
|
||||
if text:
|
||||
text = text.text.strip()
|
||||
|
||||
web_url = item.find('link')
|
||||
if web_url:
|
||||
web_url = web_url.text.strip()
|
||||
elif rss_guid and rss_guid.get('isPermalink'):
|
||||
web_url = rss_guid.text
|
||||
|
||||
if web_url and '://' not in web_url:
|
||||
web_url = None
|
||||
|
||||
published = item.find('pubDate')
|
||||
if published:
|
||||
published = published.text
|
||||
published = helpers.dateutil_parse(published)
|
||||
published = published.timestamp()
|
||||
else:
|
||||
published = 0
|
||||
|
||||
if rss_guid:
|
||||
rss_guid = rss_guid.text.strip()
|
||||
elif web_url:
|
||||
rss_guid = web_url
|
||||
elif title:
|
||||
rss_guid = f'{feed.id}_{title}'
|
||||
elif published:
|
||||
rss_guid = f'{feed.id}_{published}'
|
||||
|
||||
if not rss_guid:
|
||||
raise exceptions.NoGUID(item)
|
||||
|
||||
duplicate = self._get_duplicate_news(feed=feed, guid=rss_guid)
|
||||
if duplicate:
|
||||
log.loud('Skipping duplicate news, feed=%s, guid=%s', feed.id, rss_guid)
|
||||
return BDBNewsMixin.DUPLICATE_BAIL
|
||||
|
||||
comments_url = item.find('comments')
|
||||
if comments_url is not None:
|
||||
comments_url = comments_url.text
|
||||
|
||||
raw_authors = item.find_all('author')
|
||||
authors = []
|
||||
for raw_author in raw_authors:
|
||||
author = raw_author.text.strip()
|
||||
if author:
|
||||
author = {
|
||||
'name': author,
|
||||
}
|
||||
authors.append(author)
|
||||
|
||||
raw_enclosures = item.find_all('enclosure')
|
||||
enclosures = []
|
||||
for raw_enclosure in raw_enclosures:
|
||||
enclosure = {
|
||||
'type': raw_enclosure.get('type', None),
|
||||
'url': raw_enclosure.get('url', None),
|
||||
'size': raw_enclosure.get('length', None),
|
||||
}
|
||||
|
||||
if enclosure.get('size') is not None:
|
||||
enclosure['size'] = int(enclosure['size'])
|
||||
|
||||
enclosures.append(enclosure)
|
||||
|
||||
news = self.add_news(
|
||||
authors=authors,
|
||||
comments_url=comments_url,
|
||||
enclosures=enclosures,
|
||||
feed=feed,
|
||||
published=published,
|
||||
rss_guid=rss_guid,
|
||||
text=text,
|
||||
title=title,
|
||||
updated=published,
|
||||
web_url=web_url,
|
||||
)
|
||||
return news
|
||||
|
||||
def _ingest_news_atom(self, soup, feed):
|
||||
atom_feed = soup.find('feed')
|
||||
|
||||
if not atom_feed:
|
||||
raise exceptions.BadXML('No feed element.')
|
||||
|
||||
for entry in atom_feed.find_all('entry'):
|
||||
news = self._ingest_one_news_atom(entry, feed)
|
||||
if news is not BDBNewsMixin.DUPLICATE_BAIL:
|
||||
yield news
|
||||
|
||||
def _ingest_news_rss(self, soup, feed):
|
||||
rss = soup.find('rss')
|
||||
|
||||
# This won't happen under normal circumstances since Feed.refresh would
|
||||
# have raised already. But including these checks here in case user
|
||||
# calls directly.
|
||||
if not rss:
|
||||
raise exceptions.BadXML('No rss element.')
|
||||
|
||||
channel = rss.find('channel')
|
||||
|
||||
if not channel:
|
||||
raise exceptions.BadXML('No channel element.')
|
||||
|
||||
for item in channel.find_all('item'):
|
||||
news = self._ingest_one_news_rss(item, feed)
|
||||
if news is not BDBNewsMixin.DUPLICATE_BAIL:
|
||||
yield news
|
||||
|
||||
@worms.transaction
|
||||
def ingest_news_xml(self, soup:bs4.BeautifulSoup, feed):
|
||||
if soup.rss:
|
||||
newss = self._ingest_news_rss(soup, feed)
|
||||
elif soup.feed:
|
||||
newss = self._ingest_news_atom(soup, feed)
|
||||
else:
|
||||
raise exceptions.NeitherAtomNorRSS(soup)
|
||||
|
||||
for news in newss:
|
||||
self.process_news_through_filters(news)
|
||||
|
||||
####################################################################################################
|
||||
|
||||
class BringDB(
|
||||
BDBFeedMixin,
|
||||
BDBFilterMixin,
|
||||
BDBNewsMixin,
|
||||
worms.DatabaseWithCaching,
|
||||
):
|
||||
def __init__(
|
||||
self,
|
||||
data_directory=None,
|
||||
*,
|
||||
create=False,
|
||||
skip_version_check=False,
|
||||
):
|
||||
'''
|
||||
data_directory:
|
||||
This directory will contain the sql file and anything else needed by
|
||||
the process. The directory is the database for all intents
|
||||
and purposes.
|
||||
|
||||
create:
|
||||
If True, the data_directory will be created if it does not exist.
|
||||
If False, we expect that data_directory and the sql file exist.
|
||||
|
||||
skip_version_check:
|
||||
Skip the version check so that you don't get DatabaseOutOfDate.
|
||||
Beware of modifying any data in this state.
|
||||
'''
|
||||
super().__init__()
|
||||
|
||||
# DATA DIR PREP
|
||||
if data_directory is not None:
|
||||
pass
|
||||
else:
|
||||
data_directory = pathclass.cwd().with_child(constants.DEFAULT_DATADIR)
|
||||
|
||||
if isinstance(data_directory, str):
|
||||
data_directory = helpers.remove_path_badchars(data_directory, allowed=':/\\')
|
||||
self.data_directory = pathclass.Path(data_directory)
|
||||
|
||||
if self.data_directory.exists and not self.data_directory.is_dir:
|
||||
raise exceptions.BadDataDirectory(self.data_directory.absolute_path)
|
||||
|
||||
# DATABASE / WORMS
|
||||
self._init_sql(create=create, skip_version_check=skip_version_check)
|
||||
|
||||
# WORMS
|
||||
self.id_type = int
|
||||
self._init_column_index()
|
||||
self._init_caches()
|
||||
|
||||
def _check_version(self):
|
||||
'''
|
||||
Compare database's user_version against constants.DATABASE_VERSION,
|
||||
raising exceptions.DatabaseOutOfDate if not correct.
|
||||
'''
|
||||
existing = self.execute('PRAGMA user_version').fetchone()[0]
|
||||
if existing != constants.DATABASE_VERSION:
|
||||
raise exceptions.DatabaseOutOfDate(
|
||||
existing=existing,
|
||||
new=constants.DATABASE_VERSION,
|
||||
filepath=self.data_directory,
|
||||
)
|
||||
|
||||
def _first_time_setup(self):
|
||||
log.info('Running first-time database setup.')
|
||||
self.executescript(constants.DB_INIT)
|
||||
self.commit()
|
||||
|
||||
def _init_caches(self):
|
||||
self.caches = {
|
||||
objects.Feed: cacheclass.Cache(maxlen=2000),
|
||||
objects.Filter: cacheclass.Cache(maxlen=1000),
|
||||
objects.News: cacheclass.Cache(maxlen=20000),
|
||||
}
|
||||
|
||||
def _init_column_index(self):
|
||||
self.COLUMNS = constants.SQL_COLUMNS
|
||||
self.COLUMN_INDEX = constants.SQL_INDEX
|
||||
|
||||
def _init_sql(self, create, skip_version_check):
|
||||
self.database_filepath = self.data_directory.with_child(constants.DEFAULT_DBNAME)
|
||||
existing_database = self.database_filepath.exists
|
||||
|
||||
if not existing_database and not create:
|
||||
msg = f'"{self.database_filepath.absolute_path}" does not exist and create is off.'
|
||||
raise FileNotFoundError(msg)
|
||||
|
||||
self.data_directory.makedirs(exist_ok=True)
|
||||
log.debug('Connecting to sqlite file "%s".', self.database_filepath.absolute_path)
|
||||
self.sql = sqlite3.connect(self.database_filepath.absolute_path)
|
||||
self.sql.row_factory = sqlite3.Row
|
||||
|
||||
if existing_database:
|
||||
if not skip_version_check:
|
||||
self._check_version()
|
||||
self._load_pragmas()
|
||||
else:
|
||||
self._first_time_setup()
|
||||
|
||||
def _load_pragmas(self):
|
||||
log.debug('Reloading pragmas.')
|
||||
self.executescript(constants.DB_PRAGMAS)
|
||||
self.commit()
|
||||
|
||||
@classmethod
|
||||
def closest_bringdb(cls, path='.', *args, **kwargs):
|
||||
'''
|
||||
Starting from the given path and climbing upwards towards the filesystem
|
||||
root, look for an existing BringRSS data directory and return the
|
||||
BringDB object. If none exists, raise exceptions.NoClosestBringDB.
|
||||
'''
|
||||
path = pathclass.Path(path)
|
||||
starting = path
|
||||
|
||||
while True:
|
||||
possible = path.with_child(constants.DEFAULT_DATADIR)
|
||||
if possible.is_dir:
|
||||
break
|
||||
parent = path.parent
|
||||
if path == parent:
|
||||
raise exceptions.NoClosestBringDB(starting.absolute_path)
|
||||
path = parent
|
||||
|
||||
path = possible
|
||||
log.debug('Found closest BringDB at "%s".', path.absolute_path)
|
||||
bringdb = cls(
|
||||
data_directory=path,
|
||||
create=False,
|
||||
*args,
|
||||
**kwargs,
|
||||
)
|
||||
return bringdb
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
def __repr__(self):
|
||||
return f'BringDB(data_directory={self.data_directory})'
|
||||
|
||||
def close(self) -> None:
|
||||
super().close()
|
||||
|
||||
def generate_id(self, thing_class) -> int:
|
||||
'''
|
||||
Create a new ID number that is unique to the given table.
|
||||
'''
|
||||
if not issubclass(thing_class, objects.ObjectBase):
|
||||
raise TypeError(thing_class)
|
||||
|
||||
table = thing_class.table
|
||||
|
||||
while True:
|
||||
id = RNG.getrandbits(32)
|
||||
exists = self.select_one(f'SELECT 1 FROM {table} WHERE id == ?', [id])
|
||||
if not exists:
|
||||
return id
|
||||
349
bringrss/constants.py
Normal file
349
bringrss/constants.py
Normal file
|
|
@ -0,0 +1,349 @@
|
|||
import requests
|
||||
|
||||
from voussoirkit import sqlhelpers
|
||||
|
||||
DATABASE_VERSION = 1
|
||||
DB_VERSION_PRAGMA = f'''
|
||||
PRAGMA user_version = {DATABASE_VERSION};
|
||||
'''
|
||||
|
||||
DB_PRAGMAS = f'''
|
||||
-- 50 MB cache
|
||||
PRAGMA cache_size = -50000;
|
||||
PRAGMA foreign_keys = ON;
|
||||
'''
|
||||
|
||||
DB_INIT = f'''
|
||||
BEGIN;
|
||||
{DB_PRAGMAS}
|
||||
{DB_VERSION_PRAGMA}
|
||||
----------------------------------------------------------------------------------------------------
|
||||
CREATE TABLE IF NOT EXISTS feeds(
|
||||
id INT PRIMARY KEY NOT NULL,
|
||||
parent_id INT,
|
||||
rss_url TEXT,
|
||||
web_url TEXT,
|
||||
title TEXT,
|
||||
description TEXT,
|
||||
created INT,
|
||||
refresh_with_others INT NOT NULL,
|
||||
last_refresh INT NOT NULL,
|
||||
last_refresh_attempt INT NOT NULL,
|
||||
last_refresh_error TEXT,
|
||||
autorefresh_interval INT NOT NULL,
|
||||
http_headers TEXT,
|
||||
isolate_guids INT NOT NULL,
|
||||
icon BLOB,
|
||||
ui_order_rank INT
|
||||
);
|
||||
CREATE INDEX IF NOT EXISTS index_feeds_id on feeds(id);
|
||||
----------------------------------------------------------------------------------------------------
|
||||
CREATE TABLE IF NOT EXISTS filters(
|
||||
id INT PRIMARY KEY NOT NULL,
|
||||
name TEXT,
|
||||
created INT,
|
||||
conditions TEXT NOT NULL,
|
||||
actions TEXT NOT NULL
|
||||
);
|
||||
----------------------------------------------------------------------------------------------------
|
||||
CREATE TABLE IF NOT EXISTS news(
|
||||
id INT PRIMARY KEY NOT NULL,
|
||||
feed_id INT NOT NULL,
|
||||
original_feed_id INT NOT NULL,
|
||||
rss_guid TEXT NOT NULL,
|
||||
published INT,
|
||||
updated INT,
|
||||
title TEXT,
|
||||
text TEXT,
|
||||
web_url TEXT,
|
||||
comments_url TEXT,
|
||||
created INT,
|
||||
read INT NOT NULL,
|
||||
recycled INT NOT NULL,
|
||||
-- The authors and enclosures are stored as a JSON list of dicts. Normally I
|
||||
-- don't like to store JSON in my databases, but I'm really not interested
|
||||
-- in breaking this out in a many-to-many table to achieve proper normal
|
||||
-- form. The quantity of enclosures is probably going to be low enough, disk
|
||||
-- space is cheap enough, and for the time being we have no SQL queries
|
||||
-- against the enclosure fields to justify a perf difference.
|
||||
authors TEXT,
|
||||
enclosures TEXT,
|
||||
FOREIGN KEY(feed_id) REFERENCES feeds(id)
|
||||
);
|
||||
CREATE INDEX IF NOT EXISTS index_news_id on news(id);
|
||||
CREATE INDEX IF NOT EXISTS index_news_feed_id on news(feed_id);
|
||||
|
||||
-- Not used very often, but when you switch a feed's isolate_guids setting on
|
||||
-- and off, we need to rewrite the rss_guid for all news items from that feed,
|
||||
-- so having an index there really helps.
|
||||
CREATE INDEX IF NOT EXISTS index_news_original_feed_id on news(original_feed_id);
|
||||
|
||||
-- This will be the most commonly used search index. We search for news that is
|
||||
-- not read or recycled, ordered by published desc, and belongs to one of
|
||||
-- several feeds (feed or folder of feeds).
|
||||
CREATE INDEX IF NOT EXISTS index_news_recycled_read_published_feed_id on news(recycled, read, published, feed_id);
|
||||
|
||||
-- Less common but same idea. Finding read + unread news that's not recycled,
|
||||
-- published desc, from your feed or folder.
|
||||
CREATE INDEX IF NOT EXISTS index_news_recycled_published_feed_id on news(recycled, published, feed_id);
|
||||
|
||||
-- Used to figure out which incoming news is new and which already exist.
|
||||
CREATE INDEX IF NOT EXISTS index_news_guid on news(rss_guid);
|
||||
----------------------------------------------------------------------------------------------------
|
||||
|
||||
----------------------------------------------------------------------------------------------------
|
||||
CREATE TABLE IF NOT EXISTS feed_filter_rel(
|
||||
feed_id INT NOT NULL,
|
||||
filter_id INT NOT NULL,
|
||||
order_rank INT NOT NULL,
|
||||
FOREIGN KEY(feed_id) REFERENCES feeds(id),
|
||||
FOREIGN KEY(filter_id) REFERENCES filters(id),
|
||||
PRIMARY KEY(feed_id, filter_id)
|
||||
);
|
||||
----------------------------------------------------------------------------------------------------
|
||||
COMMIT;
|
||||
'''
|
||||
SQL_COLUMNS = sqlhelpers.extract_table_column_map(DB_INIT)
|
||||
SQL_INDEX = sqlhelpers.reverse_table_column_map(SQL_COLUMNS)
|
||||
|
||||
DEFAULT_DATADIR = '_bringrss'
|
||||
DEFAULT_DBNAME = 'bringrss.db'
|
||||
|
||||
# Normally I don't even put version numbers on my projects, but since we're
|
||||
# making requests to third parties its fair for them to know in case our HTTP
|
||||
# behavior changes.
|
||||
VERSION = '0.0.1'
|
||||
http_session = requests.Session()
|
||||
http_session.headers['User-Agent'] = f'BringRSS v{VERSION} github.com/voussoir/bringrss'
|
||||
|
||||
# Thank you h-j-13
|
||||
# https://stackoverflow.com/a/54629675/5430534
|
||||
DATEUTIL_TZINFOS = {
|
||||
'A': 1 * 3600,
|
||||
'ACDT': 10.5 * 3600,
|
||||
'ACST': 9.5 * 3600,
|
||||
'ACT': -5 * 3600,
|
||||
'ACWST': 8.75 * 3600,
|
||||
'ADT': 4 * 3600,
|
||||
'AEDT': 11 * 3600,
|
||||
'AEST': 10 * 3600,
|
||||
'AET': 10 * 3600,
|
||||
'AFT': 4.5 * 3600,
|
||||
'AKDT': -8 * 3600,
|
||||
'AKST': -9 * 3600,
|
||||
'ALMT': 6 * 3600,
|
||||
'AMST': -3 * 3600,
|
||||
'AMT': -4 * 3600,
|
||||
'ANAST': 12 * 3600,
|
||||
'ANAT': 12 * 3600,
|
||||
'AQTT': 5 * 3600,
|
||||
'ART': -3 * 3600,
|
||||
'AST': 3 * 3600,
|
||||
'AT': -4 * 3600,
|
||||
'AWDT': 9 * 3600,
|
||||
'AWST': 8 * 3600,
|
||||
'AZOST': 0 * 3600,
|
||||
'AZOT': -1 * 3600,
|
||||
'AZST': 5 * 3600,
|
||||
'AZT': 4 * 3600,
|
||||
'AoE': -12 * 3600,
|
||||
'B': 2 * 3600,
|
||||
'BNT': 8 * 3600,
|
||||
'BOT': -4 * 3600,
|
||||
'BRST': -2 * 3600,
|
||||
'BRT': -3 * 3600,
|
||||
'BST': 6 * 3600,
|
||||
'BTT': 6 * 3600,
|
||||
'C': 3 * 3600,
|
||||
'CAST': 8 * 3600,
|
||||
'CAT': 2 * 3600,
|
||||
'CCT': 6.5 * 3600,
|
||||
'CDT': -5 * 3600,
|
||||
'CEST': 2 * 3600,
|
||||
'CET': 1 * 3600,
|
||||
'CHADT': 13.75 * 3600,
|
||||
'CHAST': 12.75 * 3600,
|
||||
'CHOST': 9 * 3600,
|
||||
'CHOT': 8 * 3600,
|
||||
'CHUT': 10 * 3600,
|
||||
'CIDST': -4 * 3600,
|
||||
'CIST': -5 * 3600,
|
||||
'CKT': -10 * 3600,
|
||||
'CLST': -3 * 3600,
|
||||
'CLT': -4 * 3600,
|
||||
'COT': -5 * 3600,
|
||||
'CST': -6 * 3600,
|
||||
'CT': -6 * 3600,
|
||||
'CVT': -1 * 3600,
|
||||
'CXT': 7 * 3600,
|
||||
'ChST': 10 * 3600,
|
||||
'D': 4 * 3600,
|
||||
'DAVT': 7 * 3600,
|
||||
'DDUT': 10 * 3600,
|
||||
'E': 5 * 3600,
|
||||
'EASST': -5 * 3600,
|
||||
'EAST': -6 * 3600,
|
||||
'EAT': 3 * 3600,
|
||||
'ECT': -5 * 3600,
|
||||
'EDT': -4 * 3600,
|
||||
'EEST': 3 * 3600,
|
||||
'EET': 2 * 3600,
|
||||
'EGST': 0 * 3600,
|
||||
'EGT': -1 * 3600,
|
||||
'EST': -5 * 3600,
|
||||
'ET': -5 * 3600,
|
||||
'F': 6 * 3600,
|
||||
'FET': 3 * 3600,
|
||||
'FJST': 13 * 3600,
|
||||
'FJT': 12 * 3600,
|
||||
'FKST': -3 * 3600,
|
||||
'FKT': -4 * 3600,
|
||||
'FNT': -2 * 3600,
|
||||
'G': 7 * 3600,
|
||||
'GALT': -6 * 3600,
|
||||
'GAMT': -9 * 3600,
|
||||
'GET': 4 * 3600,
|
||||
'GFT': -3 * 3600,
|
||||
'GILT': 12 * 3600,
|
||||
'GMT': 0 * 3600,
|
||||
'GST': 4 * 3600,
|
||||
'GYT': -4 * 3600,
|
||||
'H': 8 * 3600,
|
||||
'HDT': -9 * 3600,
|
||||
'HKT': 8 * 3600,
|
||||
'HOVST': 8 * 3600,
|
||||
'HOVT': 7 * 3600,
|
||||
'HST': -10 * 3600,
|
||||
'I': 9 * 3600,
|
||||
'ICT': 7 * 3600,
|
||||
'IDT': 3 * 3600,
|
||||
'IOT': 6 * 3600,
|
||||
'IRDT': 4.5 * 3600,
|
||||
'IRKST': 9 * 3600,
|
||||
'IRKT': 8 * 3600,
|
||||
'IRST': 3.5 * 3600,
|
||||
'IST': 5.5 * 3600,
|
||||
'JST': 9 * 3600,
|
||||
'K': 10 * 3600,
|
||||
'KGT': 6 * 3600,
|
||||
'KOST': 11 * 3600,
|
||||
'KRAST': 8 * 3600,
|
||||
'KRAT': 7 * 3600,
|
||||
'KST': 9 * 3600,
|
||||
'KUYT': 4 * 3600,
|
||||
'L': 11 * 3600,
|
||||
'LHDT': 11 * 3600,
|
||||
'LHST': 10.5 * 3600,
|
||||
'LINT': 14 * 3600,
|
||||
'M': 12 * 3600,
|
||||
'MAGST': 12 * 3600,
|
||||
'MAGT': 11 * 3600,
|
||||
'MART': 9.5 * 3600,
|
||||
'MAWT': 5 * 3600,
|
||||
'MDT': -6 * 3600,
|
||||
'MHT': 12 * 3600,
|
||||
'MMT': 6.5 * 3600,
|
||||
'MSD': 4 * 3600,
|
||||
'MSK': 3 * 3600,
|
||||
'MST': -7 * 3600,
|
||||
'MT': -7 * 3600,
|
||||
'MUT': 4 * 3600,
|
||||
'MVT': 5 * 3600,
|
||||
'MYT': 8 * 3600,
|
||||
'N': -1 * 3600,
|
||||
'NCT': 11 * 3600,
|
||||
'NDT': 2.5 * 3600,
|
||||
'NFT': 11 * 3600,
|
||||
'NOVST': 7 * 3600,
|
||||
'NOVT': 7 * 3600,
|
||||
'NPT': 5.5 * 3600,
|
||||
'NRT': 12 * 3600,
|
||||
'NST': 3.5 * 3600,
|
||||
'NUT': -11 * 3600,
|
||||
'NZDT': 13 * 3600,
|
||||
'NZST': 12 * 3600,
|
||||
'O': -2 * 3600,
|
||||
'OMSST': 7 * 3600,
|
||||
'OMST': 6 * 3600,
|
||||
'ORAT': 5 * 3600,
|
||||
'P': -3 * 3600,
|
||||
'PDT': -7 * 3600,
|
||||
'PET': -5 * 3600,
|
||||
'PETST': 12 * 3600,
|
||||
'PETT': 12 * 3600,
|
||||
'PGT': 10 * 3600,
|
||||
'PHOT': 13 * 3600,
|
||||
'PHT': 8 * 3600,
|
||||
'PKT': 5 * 3600,
|
||||
'PMDT': -2 * 3600,
|
||||
'PMST': -3 * 3600,
|
||||
'PONT': 11 * 3600,
|
||||
'PST': -8 * 3600,
|
||||
'PT': -8 * 3600,
|
||||
'PWT': 9 * 3600,
|
||||
'PYST': -3 * 3600,
|
||||
'PYT': -4 * 3600,
|
||||
'Q': -4 * 3600,
|
||||
'QYZT': 6 * 3600,
|
||||
'R': -5 * 3600,
|
||||
'RET': 4 * 3600,
|
||||
'ROTT': -3 * 3600,
|
||||
'S': -6 * 3600,
|
||||
'SAKT': 11 * 3600,
|
||||
'SAMT': 4 * 3600,
|
||||
'SAST': 2 * 3600,
|
||||
'SBT': 11 * 3600,
|
||||
'SCT': 4 * 3600,
|
||||
'SGT': 8 * 3600,
|
||||
'SRET': 11 * 3600,
|
||||
'SRT': -3 * 3600,
|
||||
'SST': -11 * 3600,
|
||||
'SYOT': 3 * 3600,
|
||||
'T': -7 * 3600,
|
||||
'TAHT': -10 * 3600,
|
||||
'TFT': 5 * 3600,
|
||||
'TJT': 5 * 3600,
|
||||
'TKT': 13 * 3600,
|
||||
'TLT': 9 * 3600,
|
||||
'TMT': 5 * 3600,
|
||||
'TOST': 14 * 3600,
|
||||
'TOT': 13 * 3600,
|
||||
'TRT': 3 * 3600,
|
||||
'TVT': 12 * 3600,
|
||||
'U': -8 * 3600,
|
||||
'ULAST': 9 * 3600,
|
||||
'ULAT': 8 * 3600,
|
||||
'UTC': 0 * 3600,
|
||||
'UYST': -2 * 3600,
|
||||
'UYT': -3 * 3600,
|
||||
'UZT': 5 * 3600,
|
||||
'V': -9 * 3600,
|
||||
'VET': -4 * 3600,
|
||||
'VLAST': 11 * 3600,
|
||||
'VLAT': 10 * 3600,
|
||||
'VOST': 6 * 3600,
|
||||
'VUT': 11 * 3600,
|
||||
'W': -10 * 3600,
|
||||
'WAKT': 12 * 3600,
|
||||
'WARST': -3 * 3600,
|
||||
'WAST': 2 * 3600,
|
||||
'WAT': 1 * 3600,
|
||||
'WEST': 1 * 3600,
|
||||
'WET': 0 * 3600,
|
||||
'WFT': 12 * 3600,
|
||||
'WGST': -2 * 3600,
|
||||
'WGT': -3 * 3600,
|
||||
'WIB': 7 * 3600,
|
||||
'WIT': 9 * 3600,
|
||||
'WITA': 8 * 3600,
|
||||
'WST': 14 * 3600,
|
||||
'WT': 0 * 3600,
|
||||
'X': -11 * 3600,
|
||||
'Y': -12 * 3600,
|
||||
'YAKST': 10 * 3600,
|
||||
'YAKT': 9 * 3600,
|
||||
'YAPT': 10 * 3600,
|
||||
'YEKST': 6 * 3600,
|
||||
'YEKT': 5 * 3600,
|
||||
'Z': 0 * 3600,
|
||||
}
|
||||
148
bringrss/exceptions.py
Normal file
148
bringrss/exceptions.py
Normal file
|
|
@ -0,0 +1,148 @@
|
|||
from voussoirkit import stringtools
|
||||
|
||||
class ErrorTypeAdder(type):
|
||||
'''
|
||||
During definition, the Exception class will automatically receive a class
|
||||
attribute called `error_type` which is just the class's name as a string
|
||||
in the loudsnake casing style. NoSuchFeed -> NO_SUCH_FEED.
|
||||
|
||||
This is used for serialization of the exception object and should
|
||||
basically act as a status code when displaying the error to the user.
|
||||
|
||||
Thanks Unutbu
|
||||
http://stackoverflow.com/a/18126678
|
||||
'''
|
||||
def __init__(cls, name, bases, clsdict):
|
||||
type.__init__(cls, name, bases, clsdict)
|
||||
cls.error_type = stringtools.pascal_to_loudsnakes(name)
|
||||
|
||||
class BringException(Exception, metaclass=ErrorTypeAdder):
|
||||
'''
|
||||
Base type for all of the BringRSS exceptions.
|
||||
Subtypes should have a class attribute `error_message`. The error message
|
||||
may contain {format} strings which will be formatted using the
|
||||
Exception's constructor arguments.
|
||||
'''
|
||||
error_message = ''
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__()
|
||||
self.given_args = args
|
||||
self.given_kwargs = kwargs
|
||||
self.error_message = self.error_message.format(*args, **kwargs)
|
||||
self.args = (self.error_message, args, kwargs)
|
||||
|
||||
def __str__(self):
|
||||
return f'{self.error_type}: {self.error_message}'
|
||||
|
||||
def jsonify(self):
|
||||
j = {
|
||||
'type': 'error',
|
||||
'error_type': self.error_type,
|
||||
'error_message': self.error_message,
|
||||
}
|
||||
return j
|
||||
|
||||
# NO SUCH ##########################################################################################
|
||||
|
||||
class NoSuch(BringException):
|
||||
pass
|
||||
|
||||
class NoSuchFeed(NoSuch):
|
||||
error_message = 'Feed "{}" does not exist.'
|
||||
|
||||
class NoSuchFilter(NoSuch):
|
||||
error_message = 'Filter "{}" does not exist.'
|
||||
|
||||
class NoSuchNews(NoSuch):
|
||||
error_message = 'News "{}" does not exist.'
|
||||
|
||||
# XML PARSING ERRORS ###############################################################################
|
||||
|
||||
class BadXML(BringException):
|
||||
error_message = '{}'
|
||||
|
||||
class NeitherAtomNorRSS(BadXML):
|
||||
error_message = '{}'
|
||||
|
||||
class NoGUID(BadXML):
|
||||
error_message = '{}'
|
||||
|
||||
# FEED ERRORS ######################################################################################
|
||||
|
||||
class HTTPError(BringException):
|
||||
error_message = '{}'
|
||||
|
||||
class InvalidHTTPHeaders(BringException):
|
||||
error_message = '{}'
|
||||
|
||||
# FILTER ERRORS ####################################################################################
|
||||
|
||||
class FeedStillInUse(BringException):
|
||||
error_message = 'Cannot delete {feed} because it is used by {filters}.'
|
||||
|
||||
class FilterStillInUse(BringException):
|
||||
error_message = 'Cannot delete {filter} because it is used by feeds {feeds}.'
|
||||
|
||||
class InvalidFilter(BringException):
|
||||
error_message = '{}'
|
||||
|
||||
class InvalidFilterAction(InvalidFilter):
|
||||
error_message = '{}'
|
||||
|
||||
class InvalidFilterCondition(InvalidFilter):
|
||||
error_message = '{}'
|
||||
|
||||
# GENERAL ERRORS ###################################################################################
|
||||
|
||||
class BadDataDirectory(BringException):
|
||||
'''
|
||||
Raised by BringDB __init__ if the requested data_directory is invalid.
|
||||
'''
|
||||
error_message = 'Bad data directory "{}"'
|
||||
|
||||
OUTOFDATE = '''
|
||||
Database is out of date. {existing} should be {new}.
|
||||
Please run utilities\\database_upgrader.py "{filepath.absolute_path}"
|
||||
'''.strip()
|
||||
class DatabaseOutOfDate(BringException):
|
||||
'''
|
||||
Raised by BringDB __init__ if the user's database is behind.
|
||||
'''
|
||||
error_message = OUTOFDATE
|
||||
|
||||
class NoClosestBringDB(BringException):
|
||||
'''
|
||||
For calls to BringDB.closest_photodb where none exists between cwd and
|
||||
drive root.
|
||||
'''
|
||||
error_message = 'There is no BringDB in "{}" or its parents.'
|
||||
|
||||
class NotExclusive(BringException):
|
||||
'''
|
||||
For when two or more mutually exclusive actions have been requested.
|
||||
'''
|
||||
error_message = 'One and only one of {} must be passed.'
|
||||
|
||||
class OrderByBadColumn(BringException):
|
||||
'''
|
||||
For when the user tries to orderby a column that does not exist or is
|
||||
not allowed.
|
||||
'''
|
||||
error_message = '"{column}" is not a sortable column.'
|
||||
|
||||
class OrderByBadDirection(BringException):
|
||||
'''
|
||||
For when the user tries to orderby a direction that is not asc or desc.
|
||||
'''
|
||||
error_message = 'You can\'t order "{column}" by "{direction}". Should be asc or desc.'
|
||||
|
||||
class OrderByInvalid(BringException):
|
||||
'''
|
||||
For when the orderby request cannot be parsed into column and direction.
|
||||
For example, it contains too many hyphens like a-b-c.
|
||||
|
||||
If the column and direction can be parsed but are invalid, use
|
||||
OrderByBadColumn or OrderByBadDirection
|
||||
'''
|
||||
error_message = 'Invalid orderby request "{request}".'
|
||||
163
bringrss/helpers.py
Normal file
163
bringrss/helpers.py
Normal file
|
|
@ -0,0 +1,163 @@
|
|||
import bs4
|
||||
import datetime
|
||||
import dateutil.parser
|
||||
import importlib
|
||||
import sys
|
||||
|
||||
from . import constants
|
||||
|
||||
from voussoirkit import cacheclass
|
||||
from voussoirkit import httperrors
|
||||
from voussoirkit import pathclass
|
||||
from voussoirkit import vlogging
|
||||
|
||||
log = vlogging.get_logger(__name__)
|
||||
|
||||
_xml_etag_cache = cacheclass.Cache(maxlen=100)
|
||||
|
||||
def dateutil_parse(string):
|
||||
return dateutil.parser.parse(string, tzinfos=constants.DATEUTIL_TZINFOS)
|
||||
|
||||
def fetch_xml(url, headers={}) -> bs4.BeautifulSoup:
|
||||
log.debug('Fetching %s.', url)
|
||||
response = constants.http_session.get(url, headers=headers)
|
||||
httperrors.raise_for_status(response)
|
||||
soup = bs4.BeautifulSoup(response.text, 'xml')
|
||||
return soup
|
||||
|
||||
def fetch_xml_cached(url, headers={}) -> bs4.BeautifulSoup:
|
||||
'''
|
||||
Fetch the RSS / Atom feed, using a local cache to take advantage of HTTP304
|
||||
responses.
|
||||
'''
|
||||
cached = _xml_etag_cache.get(url)
|
||||
if cached and cached['request_headers'] == headers:
|
||||
headers = headers.copy()
|
||||
headers['if-none-match'] = cached['etag']
|
||||
|
||||
# To do: use expires / cache-control to avoid making the request at all.
|
||||
log.debug('Fetching %s.', url)
|
||||
response = constants.http_session.get(url, headers=headers)
|
||||
httperrors.raise_for_status(response)
|
||||
|
||||
if cached and response.status_code == 304:
|
||||
# Consider: after returning the cached text, it will still go through
|
||||
# the rest of the xml parsing and news ingesting steps even though it
|
||||
# will almost certainly add nothing new. But I say almost certainly
|
||||
# because you could have changed feed settings like isolate_guids.
|
||||
# May be room for optimization but it's not worth creating weird edge
|
||||
# cases over.
|
||||
log.debug('304 Using cached XML for %s.', url)
|
||||
response_text = cached['text']
|
||||
else:
|
||||
response_text = response.text
|
||||
if response.headers.get('etag'):
|
||||
cached = {
|
||||
'request_headers': headers,
|
||||
'etag': response.headers['etag'],
|
||||
'text': response_text,
|
||||
}
|
||||
_xml_etag_cache[url] = cached
|
||||
|
||||
soup = bs4.BeautifulSoup(response_text, 'xml')
|
||||
return soup
|
||||
|
||||
def import_module_by_path(path):
|
||||
'''
|
||||
Raises pathclass.NotFile if file does not exist.
|
||||
Raises ValueError if basename cannot be a Python identifier.
|
||||
'''
|
||||
given_path = path
|
||||
path = pathclass.Path(path)
|
||||
path.assert_is_file()
|
||||
name = path.basename.split('.', 1)[0]
|
||||
if not name.isidentifier():
|
||||
raise ValueError(given_path)
|
||||
_syspath = sys.path
|
||||
_sysmodules = sys.modules.copy()
|
||||
sys.path = [path.parent.absolute_path]
|
||||
module = importlib.import_module(name)
|
||||
sys.path = _syspath
|
||||
sys.modules = _sysmodules
|
||||
return module
|
||||
|
||||
@staticmethod
|
||||
def normalize_int_or_none(x):
|
||||
if x is None:
|
||||
return None
|
||||
|
||||
if isinstance(x, int):
|
||||
return x
|
||||
|
||||
if isinstance(x, float):
|
||||
return int(x)
|
||||
|
||||
raise TypeError(f'{x} should be int or None, not {type(x)}.')
|
||||
|
||||
@staticmethod
|
||||
def normalize_string_blank_to_none(string):
|
||||
if string is None:
|
||||
return None
|
||||
|
||||
if not isinstance(string, str):
|
||||
raise TypeError(string)
|
||||
|
||||
string = string.strip()
|
||||
if not string:
|
||||
return None
|
||||
|
||||
return string
|
||||
|
||||
@staticmethod
|
||||
def normalize_string_strip(string):
|
||||
if not isinstance(string, str):
|
||||
raise TypeError(string)
|
||||
|
||||
return string.strip()
|
||||
|
||||
@staticmethod
|
||||
def normalize_string_not_blank(string):
|
||||
if not isinstance(string, str):
|
||||
raise TypeError(string)
|
||||
|
||||
string = string.strip()
|
||||
if not string:
|
||||
raise ValueError(string)
|
||||
|
||||
return string
|
||||
|
||||
def now(timestamp=True):
|
||||
'''
|
||||
Return the current UTC timestamp or datetime object.
|
||||
'''
|
||||
n = datetime.datetime.now(datetime.timezone.utc)
|
||||
if timestamp:
|
||||
return n.timestamp()
|
||||
return n
|
||||
|
||||
def pick_web_url_atom(entry:bs4.BeautifulSoup):
|
||||
best_web_url = entry.find('link', {'rel': 'alternate', 'type': 'text/html'}, recursive=False)
|
||||
if best_web_url:
|
||||
return best_web_url['href']
|
||||
|
||||
alternate_url = entry.find('link', {'rel': 'alternate'}, recursive=False)
|
||||
if alternate_url:
|
||||
return alternate_url['href']
|
||||
|
||||
link = entry.find('link', recursive=False)
|
||||
if link:
|
||||
return link['href']
|
||||
|
||||
return None
|
||||
|
||||
def xml_is_atom(soup:bs4.BeautifulSoup):
|
||||
if soup.find('feed'):
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def xml_is_rss(soup:bs4.BeautifulSoup):
|
||||
if soup.find('rss') and soup.find('rss').find('channel'):
|
||||
return True
|
||||
|
||||
return False
|
||||
1432
bringrss/objects.py
Normal file
1432
bringrss/objects.py
Normal file
File diff suppressed because it is too large
Load diff
206
bringrss_logo.svg
Normal file
206
bringrss_logo.svg
Normal file
{kind=link}
File diff suppressed because one or more lines are too long
|
After Width: | Height: | Size: 13 KiB |
91
frontends/bringrss_cli.py
Normal file
91
frontends/bringrss_cli.py
Normal file
|
|
@ -0,0 +1,91 @@
|
|||
import argparse
|
||||
import sys
|
||||
|
||||
from voussoirkit import betterhelp
|
||||
from voussoirkit import hms
|
||||
from voussoirkit import operatornotify
|
||||
from voussoirkit import pipeable
|
||||
from voussoirkit import vlogging
|
||||
|
||||
import bringrss
|
||||
|
||||
log = vlogging.getLogger(__name__, 'bringrss')
|
||||
|
||||
bringdb = None
|
||||
def load_bringdb():
|
||||
global bringdb
|
||||
if bringdb is not None:
|
||||
return
|
||||
bringdb = bringrss.bringdb.BringDB.closest_bringdb()
|
||||
|
||||
####################################################################################################
|
||||
|
||||
def init_argparse(args):
|
||||
bringdb = bringrss.bringdb.BringDB(create=True)
|
||||
bringdb.commit()
|
||||
return 0
|
||||
|
||||
def refresh_argparse(args):
|
||||
load_bringdb()
|
||||
now = bringrss.helpers.now()
|
||||
soonest = float('inf')
|
||||
for feed in list(bringdb.get_feeds()):
|
||||
next_refresh = feed.next_refresh
|
||||
if now > next_refresh:
|
||||
feed.refresh()
|
||||
elif next_refresh < soonest:
|
||||
soonest = next_refresh
|
||||
if soonest != float('inf'):
|
||||
soonest = hms.seconds_to_hms_letters(soonest - now)
|
||||
pipeable.stderr(f'The next soonest is in {soonest}.')
|
||||
bringdb.commit()
|
||||
return 0
|
||||
|
||||
def refresh_all_argparse(args):
|
||||
load_bringdb()
|
||||
for feed in list(bringdb.get_feeds()):
|
||||
feed.refresh()
|
||||
bringdb.commit()
|
||||
|
||||
@operatornotify.main_decorator(subject='bringrss_cli')
|
||||
@vlogging.main_decorator
|
||||
def main(argv):
|
||||
parser = argparse.ArgumentParser(
|
||||
description='''
|
||||
This is the command-line interface for BringRSS, so that you can automate
|
||||
your database and integrated it into other scripts.
|
||||
''',
|
||||
)
|
||||
|
||||
subparsers = parser.add_subparsers()
|
||||
|
||||
p_init = subparsers.add_parser(
|
||||
'init',
|
||||
description='''
|
||||
Create a new BringRSS database in the current directory.
|
||||
''',
|
||||
)
|
||||
p_init.set_defaults(func=init_argparse)
|
||||
|
||||
p_refresh = subparsers.add_parser(
|
||||
'refresh',
|
||||
description='''
|
||||
Refresh feeds if their autorefresh interval has elapsed since their
|
||||
last refresh.
|
||||
''',
|
||||
)
|
||||
p_refresh.set_defaults(func=refresh_argparse)
|
||||
|
||||
p_refresh_all = subparsers.add_parser(
|
||||
'refresh_all',
|
||||
aliases=['refresh-all'],
|
||||
description='''
|
||||
Refresh all feeds now.
|
||||
''',
|
||||
)
|
||||
p_refresh_all.set_defaults(func=refresh_all_argparse)
|
||||
|
||||
return betterhelp.go(parser, argv)
|
||||
|
||||
if __name__ == '__main__':
|
||||
raise SystemExit(main(sys.argv[1:]))
|
||||
3
frontends/bringrss_flask/__init__.py
Normal file
3
frontends/bringrss_flask/__init__.py
Normal file
|
|
@ -0,0 +1,3 @@
|
|||
from . import backend
|
||||
|
||||
__all__ = ['backend']
|
||||
4
frontends/bringrss_flask/backend/__init__.py
Normal file
4
frontends/bringrss_flask/backend/__init__.py
Normal file
|
|
@ -0,0 +1,4 @@
|
|||
from . import common
|
||||
from . import endpoints
|
||||
|
||||
site = common.site
|
||||
322
frontends/bringrss_flask/backend/common.py
Normal file
322
frontends/bringrss_flask/backend/common.py
Normal file
|
|
@ -0,0 +1,322 @@
|
|||
'''
|
||||
Do not execute this file directly.
|
||||
Use bringrss_flask_dev.py or bringrss_flask_prod.py.
|
||||
'''
|
||||
import flask; from flask import request
|
||||
import functools
|
||||
import json
|
||||
import queue
|
||||
import threading
|
||||
import time
|
||||
import traceback
|
||||
|
||||
from voussoirkit import flasktools
|
||||
from voussoirkit import pathclass
|
||||
from voussoirkit import sentinel
|
||||
from voussoirkit import vlogging
|
||||
|
||||
log = vlogging.get_logger(__name__)
|
||||
|
||||
import bringrss
|
||||
|
||||
from . import jinja_filters
|
||||
|
||||
# Flask init #######################################################################################
|
||||
|
||||
# __file__ = .../bringrss_flask/backend/common.py
|
||||
# root_dir = .../bringrss_flask
|
||||
root_dir = pathclass.Path(__file__).parent.parent
|
||||
|
||||
TEMPLATE_DIR = root_dir.with_child('templates')
|
||||
STATIC_DIR = root_dir.with_child('static')
|
||||
FAVICON_PATH = STATIC_DIR.with_child('favicon.png')
|
||||
BROWSER_CACHE_DURATION = 180
|
||||
|
||||
site = flask.Flask(
|
||||
__name__,
|
||||
template_folder=TEMPLATE_DIR.absolute_path,
|
||||
static_folder=STATIC_DIR.absolute_path,
|
||||
)
|
||||
site.config.update(
|
||||
SEND_FILE_MAX_AGE_DEFAULT=BROWSER_CACHE_DURATION,
|
||||
TEMPLATES_AUTO_RELOAD=True,
|
||||
)
|
||||
site.jinja_env.add_extension('jinja2.ext.do')
|
||||
site.jinja_env.globals['INF'] = float('inf')
|
||||
site.jinja_env.trim_blocks = True
|
||||
site.jinja_env.lstrip_blocks = True
|
||||
jinja_filters.register_all(site)
|
||||
site.localhost_only = False
|
||||
site.demo_mode = False
|
||||
|
||||
# Response wrappers ################################################################################
|
||||
|
||||
def catch_bringrss_exception(endpoint):
|
||||
'''
|
||||
If an bringrssException is raised, automatically catch it and convert it
|
||||
into a json response so that the user doesn't receive error 500.
|
||||
'''
|
||||
@functools.wraps(endpoint)
|
||||
def wrapped(*args, **kwargs):
|
||||
try:
|
||||
return endpoint(*args, **kwargs)
|
||||
except bringrss.exceptions.BringException as exc:
|
||||
if isinstance(exc, bringrss.exceptions.NoSuch):
|
||||
status = 404
|
||||
else:
|
||||
status = 400
|
||||
response = flasktools.json_response(exc.jsonify(), status=status)
|
||||
flask.abort(response)
|
||||
return wrapped
|
||||
|
||||
@site.before_request
|
||||
def before_request():
|
||||
# Note for prod: If you see that remote_addr is always 127.0.0.1 for all
|
||||
# visitors, make sure your reverse proxy is properly setting X-Forwarded-For
|
||||
# so that werkzeug's proxyfix can set that as the remote_addr.
|
||||
# In NGINX: proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
request.is_localhost = (request.remote_addr == '127.0.0.1')
|
||||
if site.localhost_only and not request.is_localhost:
|
||||
flask.abort(403)
|
||||
|
||||
@site.after_request
|
||||
def after_request(response):
|
||||
response = flasktools.gzip_response(request, response)
|
||||
return response
|
||||
|
||||
site.route = flasktools.decorate_and_route(
|
||||
flask_app=site,
|
||||
decorators=[
|
||||
flasktools.ensure_response_type,
|
||||
functools.partial(
|
||||
flasktools.give_theme_cookie,
|
||||
cookie_name='bringrss_theme',
|
||||
default_theme='slate',
|
||||
),
|
||||
catch_bringrss_exception,
|
||||
],
|
||||
)
|
||||
|
||||
# Get functions ####################################################################################
|
||||
|
||||
def getter_wrapper(getter_function):
|
||||
def getter_wrapped(thing_id, response_type):
|
||||
if response_type not in {'html', 'json'}:
|
||||
raise TypeError(f'response_type should be html or json, not {response_type}.')
|
||||
|
||||
try:
|
||||
return getter_function(thing_id)
|
||||
|
||||
except bringrss.exceptions.BringException as exc:
|
||||
if isinstance(exc, bringrss.exceptions.NoSuch):
|
||||
status = 404
|
||||
else:
|
||||
status = 400
|
||||
|
||||
if response_type == 'html':
|
||||
flask.abort(status, exc.error_message)
|
||||
else:
|
||||
response = exc.jsonify()
|
||||
response = flasktools.json_response(response, status=status)
|
||||
flask.abort(response)
|
||||
|
||||
except Exception as exc:
|
||||
traceback.print_exc()
|
||||
if response_type == 'html':
|
||||
flask.abort(500)
|
||||
else:
|
||||
flask.abort(flasktools.json_response({}, status=500))
|
||||
|
||||
return getter_wrapped
|
||||
|
||||
@getter_wrapper
|
||||
def get_feed(feed_id):
|
||||
return bringdb.get_feed(feed_id)
|
||||
|
||||
@getter_wrapper
|
||||
def get_feeds(feed_ids):
|
||||
return bringdb.get_feeds_by_id(feed_ids)
|
||||
|
||||
@getter_wrapper
|
||||
def get_filter(filter_id):
|
||||
return bringdb.get_filter(filter_id)
|
||||
|
||||
@getter_wrapper
|
||||
def get_filters(filter_ids):
|
||||
return bringdb.get_filters_by_id(filter_ids)
|
||||
|
||||
@getter_wrapper
|
||||
def get_news(news_id):
|
||||
return bringdb.get_news(news_id)
|
||||
|
||||
@getter_wrapper
|
||||
def get_newss(news_ids):
|
||||
return bringdb.get_newss_by_id(news_ids)
|
||||
|
||||
# Other functions ##################################################################################
|
||||
|
||||
def back_url():
|
||||
return request.args.get('goto') or request.referrer or '/'
|
||||
|
||||
def render_template(request, template_name, **kwargs):
|
||||
theme = request.cookies.get('bringrss_theme', None)
|
||||
|
||||
response = flask.render_template(
|
||||
template_name,
|
||||
site=site,
|
||||
request=request,
|
||||
theme=theme,
|
||||
**kwargs,
|
||||
)
|
||||
return response
|
||||
|
||||
# Background threads ###############################################################################
|
||||
|
||||
# This item can be put in a thread's message queue, and when the thread notices
|
||||
# it, the thread will quit gracefully.
|
||||
QUIT_EVENT = sentinel.Sentinel('quit')
|
||||
|
||||
####################################################################################################
|
||||
|
||||
AUTOREFRESH_THREAD_EVENTS = queue.Queue()
|
||||
|
||||
def autorefresh_thread():
|
||||
'''
|
||||
This thread keeps an eye on the last_refresh and autorefresh_interval of all
|
||||
the feeds, and puts the feeds into the REFRESH_QUEUE when they are ready.
|
||||
|
||||
When a feed is refreshed manually, we recalculate the schedule so it does
|
||||
not autorefresh until another interval has elapsed.
|
||||
'''
|
||||
log.info('Starting autorefresh thread.')
|
||||
while True:
|
||||
if not REFRESH_QUEUE.empty():
|
||||
time.sleep(10)
|
||||
continue
|
||||
now = bringrss.helpers.now()
|
||||
soonest = now + 3600
|
||||
for feed in list(bringdb.get_feeds()):
|
||||
next_refresh = feed.next_refresh
|
||||
if now > next_refresh:
|
||||
add_feed_to_refresh_queue(feed)
|
||||
# If the refresh fails it'll try again in an hour, if it
|
||||
# succeeds it'll be one interval. We'll know for sure later but
|
||||
# this is when this auto thread will check and see.
|
||||
next_refresh = now + feed.autorefresh_interval
|
||||
|
||||
soonest = min(soonest, next_refresh)
|
||||
|
||||
now = bringrss.helpers.now()
|
||||
sleepy = soonest - now
|
||||
sleepy = max(sleepy, 30)
|
||||
sleepy = min(sleepy, 7200)
|
||||
sleepy = int(sleepy)
|
||||
log.info(f'Sleeping {sleepy} until next refresh.')
|
||||
try:
|
||||
event = AUTOREFRESH_THREAD_EVENTS.get(timeout=sleepy)
|
||||
if event is QUIT_EVENT:
|
||||
break
|
||||
except queue.Empty:
|
||||
pass
|
||||
|
||||
####################################################################################################
|
||||
|
||||
REFRESH_QUEUE = queue.Queue()
|
||||
# The Queue objects cannot be iterated and do not support membership testing.
|
||||
# We use this set to prevent the same feed being queued up for refresh twice
|
||||
# at the same time.
|
||||
_REFRESH_QUEUE_SET = set()
|
||||
|
||||
def refresh_queue_thread():
|
||||
'''
|
||||
This thread handles all Feed refreshing and sends the results out via the
|
||||
SSE channel. Whether the refresh was user-initiated by clicking on the
|
||||
"Refresh" / "Refresh all" button, or server-initiated by the autorefresh
|
||||
timer, all actual refreshing happens through here. This allows us to make
|
||||
sure we only have one refresh going on at a time and clients don't have to
|
||||
distinguish between responses to their refresh request and server-initiated
|
||||
refreshes, they can just always watch the SSE.
|
||||
'''
|
||||
def _refresh_one(feed):
|
||||
if not feed.rss_url:
|
||||
feed.clear_last_refresh_error()
|
||||
return
|
||||
|
||||
# Don't bother calculating unreads
|
||||
flasktools.send_sse(
|
||||
event='feed_refresh_started',
|
||||
data=json.dumps(feed.jsonify(unread_count=False)),
|
||||
)
|
||||
try:
|
||||
feed.refresh()
|
||||
except Exception as exc:
|
||||
log.warning('Refreshing %s encountered:\n%s', feed, traceback.format_exc())
|
||||
bringdb.commit()
|
||||
flasktools.send_sse(
|
||||
event='feed_refresh_finished',
|
||||
data=json.dumps(feed.jsonify(unread_count=True)),
|
||||
)
|
||||
|
||||
log.info('Starting refresh_queue thread.')
|
||||
while True:
|
||||
feed = REFRESH_QUEUE.get()
|
||||
if feed is QUIT_EVENT:
|
||||
break
|
||||
_refresh_one(feed)
|
||||
_REFRESH_QUEUE_SET.discard(feed)
|
||||
if REFRESH_QUEUE.empty():
|
||||
flasktools.send_sse(event='feed_refresh_queue_finished', data='')
|
||||
_REFRESH_QUEUE_SET.clear()
|
||||
|
||||
def add_feed_to_refresh_queue(feed):
|
||||
if site.demo_mode:
|
||||
return
|
||||
|
||||
if feed in _REFRESH_QUEUE_SET:
|
||||
return
|
||||
|
||||
log.debug('Adding %s to refresh queue.', feed)
|
||||
REFRESH_QUEUE.put(feed)
|
||||
_REFRESH_QUEUE_SET.add(feed)
|
||||
|
||||
def clear_refresh_queue():
|
||||
while not REFRESH_QUEUE.empty():
|
||||
feed = REFRESH_QUEUE.get_nowait()
|
||||
_REFRESH_QUEUE_SET.clear()
|
||||
|
||||
def sse_keepalive_thread():
|
||||
log.info('Starting SSE keepalive thread.')
|
||||
while True:
|
||||
flasktools.send_sse(event='keepalive', data=bringrss.helpers.now())
|
||||
time.sleep(60)
|
||||
|
||||
####################################################################################################
|
||||
|
||||
# These functions will be called by the launcher, flask_dev, flask_prod.
|
||||
|
||||
def init_bringdb(*args, **kwargs):
|
||||
global bringdb
|
||||
bringdb = bringrss.bringdb.BringDB.closest_bringdb(*args, **kwargs)
|
||||
if site.demo_mode:
|
||||
do_nothing = lambda *args, **kwargs: None
|
||||
for module in [bringrss.bringdb, bringrss.objects]:
|
||||
classes = [cls for (name, cls) in vars(module).items() if isinstance(cls, type)]
|
||||
for cls in classes:
|
||||
for (name, attribute) in vars(cls).items():
|
||||
if getattr(attribute, 'is_worms_transaction', False) is True:
|
||||
setattr(cls, name, do_nothing)
|
||||
print(cls, name, 'DO NOTHING')
|
||||
|
||||
bringdb.commit = do_nothing
|
||||
bringdb.insert = do_nothing
|
||||
bringdb.update = do_nothing
|
||||
bringdb.delete = do_nothing
|
||||
AUTOREFRESH_THREAD_EVENTS.put(QUIT_EVENT)
|
||||
AUTOREFRESH_THREAD_EVENTS.put = do_nothing
|
||||
|
||||
REFRESH_QUEUE.put(QUIT_EVENT)
|
||||
|
||||
def start_background_threads():
|
||||
threading.Thread(target=autorefresh_thread, daemon=True).start()
|
||||
threading.Thread(target=refresh_queue_thread, daemon=True).start()
|
||||
threading.Thread(target=sse_keepalive_thread, daemon=True).start()
|
||||
4
frontends/bringrss_flask/backend/endpoints/__init__.py
Normal file
4
frontends/bringrss_flask/backend/endpoints/__init__.py
Normal file
|
|
@ -0,0 +1,4 @@
|
|||
from . import basic_endpoints
|
||||
from . import feed_endpoints
|
||||
from . import filter_endpoints
|
||||
from . import news_endpoints
|
||||
|
|
@ -0,0 +1,59 @@
|
|||
import flask; from flask import request
|
||||
|
||||
from voussoirkit import flasktools
|
||||
from voussoirkit import stringtools
|
||||
from voussoirkit import vlogging
|
||||
|
||||
log = vlogging.get_logger(__name__)
|
||||
|
||||
from .. import common
|
||||
|
||||
import bringrss
|
||||
|
||||
site = common.site
|
||||
|
||||
####################################################################################################
|
||||
|
||||
@site.route('/favicon.ico')
|
||||
@site.route('/favicon.png')
|
||||
def favicon():
|
||||
return flask.send_file(common.FAVICON_PATH.absolute_path)
|
||||
|
||||
@site.route('/news.json')
|
||||
@site.route('/feed/<feed_id>/news.json')
|
||||
@flasktools.cached_endpoint(max_age=0, etag_function=lambda: common.bringdb.last_commit_id, max_urls=200)
|
||||
def get_newss_json(feed_id=None):
|
||||
if feed_id is None:
|
||||
feed = None
|
||||
else:
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
read = stringtools.truthystring(request.args.get('read', False))
|
||||
recycled = stringtools.truthystring(request.args.get('recycled', False))
|
||||
newss = common.bringdb.get_newss(feed=feed, read=read, recycled=recycled)
|
||||
response = [news.jsonify() for news in newss]
|
||||
return flasktools.json_response(response)
|
||||
|
||||
@site.route('/')
|
||||
@site.route('/feed/<feed_id>')
|
||||
def get_newss(feed_id=None):
|
||||
if feed_id is None:
|
||||
feed = None
|
||||
else:
|
||||
feed = common.get_feed(feed_id, response_type='html')
|
||||
|
||||
return common.render_template(
|
||||
request,
|
||||
'root.html',
|
||||
specific_feed=feed,
|
||||
)
|
||||
|
||||
@site.route('/about')
|
||||
def get_about():
|
||||
return common.render_template(request, 'about.html')
|
||||
|
||||
@site.route('/sse')
|
||||
def get_sse():
|
||||
response = flask.Response(flasktools.sse_generator(), mimetype='text/event-stream')
|
||||
# Skip gzip
|
||||
response.direct_passthrough = True
|
||||
return response
|
||||
250
frontends/bringrss_flask/backend/endpoints/feed_endpoints.py
Normal file
250
frontends/bringrss_flask/backend/endpoints/feed_endpoints.py
Normal file
|
|
@ -0,0 +1,250 @@
|
|||
import base64
|
||||
import flask; from flask import request
|
||||
import traceback
|
||||
|
||||
from voussoirkit import stringtools
|
||||
from voussoirkit import flasktools
|
||||
from voussoirkit import vlogging
|
||||
|
||||
log = vlogging.get_logger(__name__)
|
||||
|
||||
from .. import common
|
||||
|
||||
import bringrss
|
||||
|
||||
site = common.site
|
||||
|
||||
# Feed listings ####################################################################################
|
||||
|
||||
@site.route('/feeds.json')
|
||||
@flasktools.cached_endpoint(max_age=0, etag_function=lambda: common.bringdb.last_commit_id)
|
||||
def get_feeds_json():
|
||||
feeds = common.bringdb.get_feeds()
|
||||
response = []
|
||||
unread_counts = common.bringdb.get_bulk_unread_counts()
|
||||
for feed in feeds:
|
||||
j = feed.jsonify()
|
||||
j['unread_count'] = unread_counts.get(feed, 0)
|
||||
response.append(j)
|
||||
return flasktools.json_response(response)
|
||||
|
||||
@site.route('/feeds/add', methods=['POST'])
|
||||
def post_feeds_add():
|
||||
rss_url = request.form.get('rss_url')
|
||||
title = request.form.get('title')
|
||||
isolate_guids = request.form.get('isolate_guids', False)
|
||||
isolate_guids = stringtools.truthystring(isolate_guids)
|
||||
feed = common.bringdb.add_feed(rss_url=rss_url, title=title, isolate_guids=isolate_guids)
|
||||
|
||||
# We want to refresh the feed now and not just put it on the refresh queue,
|
||||
# because when the user gets the response to this endpoint they will
|
||||
# navigate to the /settings, and we want to have that page pre-populated
|
||||
# with the title and icon. If the feed goes to the refresh queue, the page
|
||||
# will come up blank, then get populated in the background, which is bad
|
||||
# ux. However, we need to commit first, because if the refresh fails we want
|
||||
# the user to be able to see the Feed in the ui and read its
|
||||
# last_refresh_error message.
|
||||
common.bringdb.commit()
|
||||
try:
|
||||
feed.refresh()
|
||||
common.bringdb.commit()
|
||||
except Exception:
|
||||
log.warning('Refreshing %s raised:\n%s', feed, traceback.format_exc())
|
||||
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feeds/refresh_all', methods=['POST'])
|
||||
def post_feeds_refresh_all():
|
||||
predicate = lambda feed: feed.refresh_with_others
|
||||
# The root feeds are not exempt from the predicate because the user clicked
|
||||
# the refresh all button, not the root feed specifically.
|
||||
root_feeds = [root for root in common.bringdb.get_root_feeds() if predicate(root)]
|
||||
for root_feed in root_feeds:
|
||||
for feed in root_feed.walk_children(predicate=predicate, yield_self=True):
|
||||
common.add_feed_to_refresh_queue(feed)
|
||||
return flasktools.json_response({})
|
||||
|
||||
# Individual feeds #################################################################################
|
||||
|
||||
@site.route('/feed/<feed_id>.json')
|
||||
def get_feed_json(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feed/<feed_id>/delete', methods=['POST'])
|
||||
def post_feed_delete(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
feed.delete()
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response({})
|
||||
|
||||
@site.route('/feed/<feed_id>/icon.png')
|
||||
def get_feed_icon(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='html')
|
||||
|
||||
if feed.icon:
|
||||
headers = {'Cache-Control': f'max-age={common.BROWSER_CACHE_DURATION}'}
|
||||
return flask.Response(feed.icon, mimetype='image/png', headers=headers)
|
||||
elif feed.rss_url:
|
||||
basic = common.STATIC_DIR.with_child('basic_icons').with_child('rss.png')
|
||||
return flask.send_file(basic.absolute_path)
|
||||
else:
|
||||
basic = common.STATIC_DIR.with_child('basic_icons').with_child('folder.png')
|
||||
return flask.send_file(basic.absolute_path)
|
||||
|
||||
@site.route('/feed/<feed_id>/refresh', methods=['POST'])
|
||||
def post_feed_refresh(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
|
||||
predicate = lambda child: child.refresh_with_others
|
||||
# We definitely want to refresh this feed regardless of the predicate,
|
||||
# because that's what was requested.
|
||||
feeds = list(feed.walk_children(predicate=predicate, yield_self=True))
|
||||
for feed in feeds:
|
||||
common.add_feed_to_refresh_queue(feed)
|
||||
|
||||
return flasktools.json_response({})
|
||||
|
||||
@site.route('/feed/<feed_id>/settings')
|
||||
def get_feed_settings(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='html')
|
||||
feed_filters = list(feed.get_filters())
|
||||
available_filters = set(common.bringdb.get_filters())
|
||||
available_filters.difference_update(feed_filters)
|
||||
return common.render_template(
|
||||
request,
|
||||
'feed_settings.html',
|
||||
feed=feed,
|
||||
feed_filters=feed_filters,
|
||||
available_filters=available_filters,
|
||||
)
|
||||
|
||||
@site.route('/feed/<feed_id>/set_autorefresh_interval', methods=['POST'])
|
||||
@flasktools.required_fields(['autorefresh_interval'])
|
||||
def post_feed_set_autorefresh_interval(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
autorefresh_interval = request.form['autorefresh_interval']
|
||||
try:
|
||||
autorefresh_interval = int(autorefresh_interval)
|
||||
except ValueError:
|
||||
return flasktools.json_response({}, status=400)
|
||||
|
||||
if autorefresh_interval != feed.autorefresh_interval:
|
||||
feed.set_autorefresh_interval(autorefresh_interval)
|
||||
common.bringdb.commit()
|
||||
# Wake up the autorefresh thread so it can recalculate its schedule.
|
||||
common.AUTOREFRESH_THREAD_EVENTS.put("wake up!")
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feed/<feed_id>/set_filters', methods=['POST'])
|
||||
@flasktools.required_fields(['filter_ids'])
|
||||
def post_feed_set_filters(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
filter_ids = stringtools.comma_space_split(request.form['filter_ids'])
|
||||
filters = [common.get_filter(id, response_type='json') for id in filter_ids]
|
||||
feed.set_filters(filters)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(feed.jsonify(filters=True))
|
||||
|
||||
@site.route('/feed/<feed_id>/set_http_headers', methods=['POST'])
|
||||
@flasktools.required_fields(['http_headers'])
|
||||
def post_feed_set_http_headers(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
feed.set_http_headers(request.form['http_headers'])
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feed/<feed_id>/set_icon', methods=['POST'])
|
||||
@flasktools.required_fields(['image_base64'])
|
||||
def post_feed_set_icon(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
image_base64 = request.form['image_base64']
|
||||
image_base64 = image_base64.split(';base64,')[-1]
|
||||
image_binary = base64.b64decode(image_base64)
|
||||
feed.set_icon(image_binary)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feed/<feed_id>/set_isolate_guids', methods=['POST'])
|
||||
@flasktools.required_fields(['isolate_guids'])
|
||||
def post_feed_set_isolate_guids(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
try:
|
||||
isolate_guids = stringtools.truthystring(request.form['isolate_guids'])
|
||||
except ValueError:
|
||||
return flasktools.json_response({}, status=400)
|
||||
feed.set_isolate_guids(isolate_guids)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feed/<feed_id>/set_parent', methods=['POST'])
|
||||
@flasktools.required_fields(['parent_id'])
|
||||
def post_feed_set_parent(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
|
||||
parent_id = request.form['parent_id']
|
||||
if parent_id == '':
|
||||
parent = None
|
||||
else:
|
||||
parent = common.get_feed(parent_id, response_type='json')
|
||||
|
||||
ui_order_rank = request.form.get('ui_order_rank', None)
|
||||
if ui_order_rank is not None:
|
||||
ui_order_rank = float(ui_order_rank)
|
||||
|
||||
if parent != feed.parent or ui_order_rank != feed.ui_order_rank:
|
||||
feed.set_parent(parent, ui_order_rank=ui_order_rank)
|
||||
common.bringdb.commit()
|
||||
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feed/<feed_id>/set_refresh_with_others', methods=['POST'])
|
||||
@flasktools.required_fields(['refresh_with_others'])
|
||||
def post_feed_set_refresh_with_others(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
refresh_with_others = stringtools.truthystring(request.form['refresh_with_others'])
|
||||
if refresh_with_others != feed.refresh_with_others:
|
||||
feed.set_refresh_with_others(refresh_with_others)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feed/<feed_id>/set_rss_url', methods=['POST'])
|
||||
@flasktools.required_fields(['rss_url'])
|
||||
def post_feed_set_rss_url(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
rss_url = request.form['rss_url']
|
||||
if rss_url != feed.rss_url:
|
||||
feed.set_rss_url(rss_url)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feed/<feed_id>/set_web_url', methods=['POST'])
|
||||
@flasktools.required_fields(['web_url'])
|
||||
def post_feed_set_web_url(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
web_url = request.form['web_url']
|
||||
if web_url != feed.web_url:
|
||||
feed.set_web_url(web_url)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feed/<feed_id>/set_title', methods=['POST'])
|
||||
@flasktools.required_fields(['title'])
|
||||
def post_feed_set_title(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
title = request.form['title']
|
||||
if title != feed.title:
|
||||
feed.set_title(title)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
|
||||
@site.route('/feed/<feed_id>/set_ui_order_rank', methods=['POST'])
|
||||
@flasktools.required_fields(['ui_order_rank'], forbid_whitespace=True)
|
||||
def post_feed_set_ui_order_rank(feed_id):
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
ui_order_rank = float(request.form['ui_order_rank'])
|
||||
if ui_order_rank != feed.ui_order_rank:
|
||||
feed.set_ui_order_rank(ui_order_rank)
|
||||
common.bringdb.reassign_ui_order_rank()
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(feed.jsonify())
|
||||
139
frontends/bringrss_flask/backend/endpoints/filter_endpoints.py
Normal file
139
frontends/bringrss_flask/backend/endpoints/filter_endpoints.py
Normal file
|
|
@ -0,0 +1,139 @@
|
|||
import flask; from flask import request
|
||||
|
||||
from voussoirkit import flasktools
|
||||
|
||||
from .. import common
|
||||
|
||||
import bringrss
|
||||
|
||||
site = common.site
|
||||
|
||||
####################################################################################################
|
||||
|
||||
@site.route('/filters.json')
|
||||
@flasktools.cached_endpoint(max_age=0, etag_function=lambda: common.bringdb.last_commit_id)
|
||||
def get_filters_json():
|
||||
filters = common.bringdb.get_filters()
|
||||
filters = sorted(filters, key=lambda filt: filt.display_name.lower())
|
||||
response = [filt.jsonify() for filt in filters]
|
||||
return flasktools.json_response(response)
|
||||
|
||||
@site.route('/filters')
|
||||
def get_filters():
|
||||
filters = common.bringdb.get_filters()
|
||||
filters = sorted(filters, key=lambda filt: filt.display_name.lower())
|
||||
return common.render_template(
|
||||
request,
|
||||
'filters.html',
|
||||
filters=filters,
|
||||
filter_class=bringrss.objects.Filter,
|
||||
specific_filter=None,
|
||||
)
|
||||
|
||||
@site.route('/filters/add', methods=['POST'])
|
||||
@flasktools.required_fields(['conditions', 'actions'], forbid_whitespace=True)
|
||||
def post_filters_add():
|
||||
name = request.form.get('name', None)
|
||||
conditions = request.form['conditions']
|
||||
actions = request.form['actions']
|
||||
filt = common.bringdb.add_filter(name=name, conditions=conditions, actions=actions)
|
||||
common.bringdb.commit()
|
||||
flasktools.send_sse(event='filters_changed', data=None)
|
||||
return flasktools.json_response(filt.jsonify())
|
||||
|
||||
@site.route('/filter/<filter_id>')
|
||||
def get_filter(filter_id):
|
||||
filt = common.get_filter(filter_id, response_type='html')
|
||||
filters = [filt]
|
||||
return common.render_template(
|
||||
request,
|
||||
'filters.html',
|
||||
filters=filters,
|
||||
filter_class=bringrss.objects.Filter,
|
||||
specific_filter=filt.id,
|
||||
)
|
||||
|
||||
@site.route('/filter/<filter_id>.json')
|
||||
def get_filter_json(filter_id):
|
||||
filt = common.get_filter(filter_id, response_type='json')
|
||||
return flasktools.json_response(filt.jsonify())
|
||||
|
||||
@site.route('/filter/<filter_id>/delete', methods=['POST'])
|
||||
def post_filter_delete(filter_id):
|
||||
filt = common.get_filter(filter_id, response_type='json')
|
||||
try:
|
||||
filt.delete()
|
||||
except bringrss.exceptions.FilterStillInUse as exc:
|
||||
return flasktools.json_response(exc.jsonify(), status=400)
|
||||
common.bringdb.commit()
|
||||
flasktools.send_sse(event='filters_changed', data=None)
|
||||
return flasktools.json_response({})
|
||||
|
||||
@site.route('/filter/<filter_id>/run_filter', methods=['POST'])
|
||||
def post_run_filter_now(filter_id):
|
||||
feed_id = request.form.get('feed_id')
|
||||
if feed_id:
|
||||
feed = common.get_feed(feed_id, response_type='json')
|
||||
else:
|
||||
feed = None
|
||||
|
||||
filt = common.get_filter(filter_id, response_type='json')
|
||||
newss = list(common.bringdb.get_newss(
|
||||
feed=feed,
|
||||
read=None,
|
||||
recycled=None,
|
||||
))
|
||||
for news in newss:
|
||||
filt.process_news(news)
|
||||
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response({})
|
||||
|
||||
@site.route('/filter/<filter_id>/set_actions', methods=['POST'])
|
||||
@flasktools.required_fields(['actions'], forbid_whitespace=True)
|
||||
def post_filter_set_actions(filter_id):
|
||||
filt = common.get_filter(filter_id, response_type='json')
|
||||
actions = request.form['actions']
|
||||
if actions != filt.actions:
|
||||
filt.set_actions(actions)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(filt.jsonify())
|
||||
|
||||
@site.route('/filter/<filter_id>/set_conditions', methods=['POST'])
|
||||
@flasktools.required_fields(['conditions'], forbid_whitespace=True)
|
||||
def post_filter_set_conditions(filter_id):
|
||||
filt = common.get_filter(filter_id, response_type='json')
|
||||
conditions = request.form['conditions']
|
||||
if conditions != filt.conditions:
|
||||
filt.set_conditions(conditions)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(filt.jsonify())
|
||||
|
||||
@site.route('/filter/<filter_id>/set_name', methods=['POST'])
|
||||
@flasktools.required_fields(['name'])
|
||||
def post_filter_set_name(filter_id):
|
||||
filt = common.get_filter(filter_id, response_type='json')
|
||||
name = request.form['name']
|
||||
if name != filt.name:
|
||||
filt.set_name(name)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(filt.jsonify())
|
||||
|
||||
@site.route('/filter/<filter_id>/update', methods=['POST'])
|
||||
def post_filter_update(filter_id):
|
||||
filt = common.get_filter(filter_id, response_type='json')
|
||||
name = request.form.get('name', None)
|
||||
if name is not None:
|
||||
filt.set_name(name)
|
||||
|
||||
conditions = request.form.get('conditions', None)
|
||||
if conditions is not None:
|
||||
filt.set_conditions(conditions)
|
||||
|
||||
actions = request.form.get('actions', None)
|
||||
if actions is not None:
|
||||
filt.set_actions(actions)
|
||||
|
||||
common.bringdb.commit()
|
||||
flasktools.send_sse(event='filters_changed', data=None)
|
||||
return flasktools.json_response(filt.jsonify())
|
||||
83
frontends/bringrss_flask/backend/endpoints/news_endpoints.py
Normal file
83
frontends/bringrss_flask/backend/endpoints/news_endpoints.py
Normal file
|
|
@ -0,0 +1,83 @@
|
|||
import flask; from flask import request
|
||||
|
||||
from voussoirkit import flasktools
|
||||
from voussoirkit import stringtools
|
||||
|
||||
from .. import common
|
||||
|
||||
import bringrss
|
||||
|
||||
site = common.site
|
||||
|
||||
####################################################################################################
|
||||
|
||||
@site.route('/news/<news_id>/set_read', methods=['POST'])
|
||||
@flasktools.required_fields(['read'], forbid_whitespace=True)
|
||||
def post_news_set_read(news_id):
|
||||
news = common.get_news(news_id, response_type='json')
|
||||
read = stringtools.truthystring(request.form['read'])
|
||||
news.set_read(read)
|
||||
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(news.jsonify())
|
||||
|
||||
@site.route('/news/<news_id>/set_recycled', methods=['POST'])
|
||||
@flasktools.required_fields(['recycled'], forbid_whitespace=True)
|
||||
def post_news_set_recycled(news_id):
|
||||
news = common.get_news(news_id, response_type='json')
|
||||
recycled = stringtools.truthystring(request.form['recycled'])
|
||||
news.set_recycled(recycled)
|
||||
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(news.jsonify())
|
||||
|
||||
@site.route('/news/<news_id>.json', methods=['GET'])
|
||||
def get_news(news_id):
|
||||
news = common.get_news(news_id, response_type='json')
|
||||
return flasktools.json_response(news.jsonify(complete=True))
|
||||
|
||||
@site.route('/news/<news_id>.json', methods=['POST'])
|
||||
def post_get_news(news_id):
|
||||
news = common.get_news(news_id, response_type='json')
|
||||
mark_read = request.form.get('set_read', None)
|
||||
mark_read = stringtools.truthystring(mark_read)
|
||||
if mark_read is not None:
|
||||
news.set_read(mark_read)
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(news.jsonify(complete=True))
|
||||
|
||||
@site.route('/batch/news/set_read', methods=['POST'])
|
||||
@flasktools.required_fields(['news_ids', 'read'], forbid_whitespace=True)
|
||||
def post_batch_set_read():
|
||||
news_ids = request.form['news_ids']
|
||||
news_ids = stringtools.comma_space_split(news_ids)
|
||||
news_ids = [int(id) for id in news_ids]
|
||||
newss = common.get_newss(news_ids, response_type='json')
|
||||
|
||||
read = stringtools.truthystring(request.form['read'])
|
||||
|
||||
return_ids = []
|
||||
for news in newss:
|
||||
news.set_read(read)
|
||||
return_ids.append(news.id)
|
||||
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(return_ids)
|
||||
|
||||
@site.route('/batch/news/set_recycled', methods=['POST'])
|
||||
@flasktools.required_fields(['news_ids', 'recycled'], forbid_whitespace=True)
|
||||
def post_batch_recycle_news():
|
||||
news_ids = request.form['news_ids']
|
||||
news_ids = stringtools.comma_space_split(news_ids)
|
||||
news_ids = [int(id) for id in news_ids]
|
||||
newss = common.get_newss(news_ids, response_type='json')
|
||||
|
||||
recycled = stringtools.truthystring(request.form['recycled'])
|
||||
|
||||
return_ids = []
|
||||
for news in newss:
|
||||
news.set_recycled(recycled)
|
||||
return_ids.append(news.id)
|
||||
|
||||
common.bringdb.commit()
|
||||
return flasktools.json_response(return_ids)
|
||||
62
frontends/bringrss_flask/backend/jinja_filters.py
Normal file
62
frontends/bringrss_flask/backend/jinja_filters.py
Normal file
|
|
@ -0,0 +1,62 @@
|
|||
import datetime
|
||||
import jinja2.filters
|
||||
|
||||
####################################################################################################
|
||||
|
||||
filter_functions = []
|
||||
global_functions = []
|
||||
|
||||
def filter_function(function):
|
||||
filter_functions.append(function)
|
||||
return function
|
||||
|
||||
def global_function(function):
|
||||
global_functions.append(function)
|
||||
return function
|
||||
|
||||
def register_all(site):
|
||||
for function in filter_functions:
|
||||
site.jinja_env.filters[function.__name__] = function
|
||||
|
||||
for function in global_functions:
|
||||
site.jinja_env.globals[function.__name__] = function
|
||||
|
||||
####################################################################################################
|
||||
|
||||
@filter_function
|
||||
def http_headers_dict_to_lines(http_headers):
|
||||
if not http_headers:
|
||||
return ''
|
||||
lines = '\n'.join(f'{key}: {value}' for (key, value) in sorted(http_headers.items()))
|
||||
return lines
|
||||
|
||||
@filter_function
|
||||
def timestamp_to_8601(timestamp):
|
||||
return datetime.datetime.utcfromtimestamp(timestamp).isoformat(' ') + ' UTC'
|
||||
|
||||
@filter_function
|
||||
def timestamp_to_8601_local(timestamp):
|
||||
return datetime.datetime.fromtimestamp(timestamp).isoformat(' ')
|
||||
|
||||
@filter_function
|
||||
def timestamp_to_string(timestamp, format):
|
||||
date = datetime.datetime.utcfromtimestamp(timestamp)
|
||||
return date.strftime(format)
|
||||
|
||||
@filter_function
|
||||
def timestamp_to_naturaldate(timestamp):
|
||||
return timestamp_to_string(timestamp, '%B %d, %Y')
|
||||
|
||||
####################################################################################################
|
||||
|
||||
@global_function
|
||||
def make_attributes(*booleans, **keyvalues):
|
||||
keyvalues = {
|
||||
key.replace('_', '-'): value
|
||||
for (key, value) in keyvalues.items()
|
||||
if value is not None
|
||||
}
|
||||
attributes = [f'{key}="{jinja2.filters.escape(value)}"' for (key, value) in keyvalues.items()]
|
||||
attributes.extend(booleans)
|
||||
attributes = ' '.join(attributes)
|
||||
return attributes
|
||||
154
frontends/bringrss_flask/bringrss_flask_dev.py
Normal file
154
frontends/bringrss_flask/bringrss_flask_dev.py
Normal file
|
|
@ -0,0 +1,154 @@
|
|||
'''
|
||||
This file is the gevent launcher for local / development use.
|
||||
'''
|
||||
import gevent.monkey; gevent.monkey.patch_all()
|
||||
import werkzeug.middleware.proxy_fix
|
||||
|
||||
import argparse
|
||||
import gevent.pywsgi
|
||||
import os
|
||||
import sys
|
||||
|
||||
from voussoirkit import betterhelp
|
||||
from voussoirkit import operatornotify
|
||||
from voussoirkit import pathclass
|
||||
from voussoirkit import vlogging
|
||||
|
||||
log = vlogging.getLogger(__name__, 'bringrss_flask_dev')
|
||||
|
||||
import bringrss
|
||||
import backend
|
||||
|
||||
site = backend.site
|
||||
site.wsgi_app = werkzeug.middleware.proxy_fix.ProxyFix(site.wsgi_app)
|
||||
site.debug = True
|
||||
|
||||
HTTPS_DIR = pathclass.Path(__file__).parent.with_child('https')
|
||||
|
||||
####################################################################################################
|
||||
|
||||
def bringrss_flask_dev(
|
||||
*,
|
||||
demo_mode,
|
||||
localhost_only,
|
||||
init,
|
||||
port,
|
||||
use_https,
|
||||
):
|
||||
if use_https is None:
|
||||
use_https = port == 443
|
||||
|
||||
if use_https:
|
||||
http = gevent.pywsgi.WSGIServer(
|
||||
listener=('0.0.0.0', port),
|
||||
application=site,
|
||||
keyfile=HTTPS_DIR.with_child('bringrss.key').absolute_path,
|
||||
certfile=HTTPS_DIR.with_child('bringrss.crt').absolute_path,
|
||||
)
|
||||
else:
|
||||
http = gevent.pywsgi.WSGIServer(
|
||||
listener=('0.0.0.0', port),
|
||||
application=site,
|
||||
)
|
||||
|
||||
if localhost_only:
|
||||
log.info('Setting localhost_only = True')
|
||||
site.localhost_only = True
|
||||
|
||||
if demo_mode:
|
||||
log.info('Setting demo_mode = True')
|
||||
site.demo_mode = True
|
||||
|
||||
if init:
|
||||
bringrss.bringdb.BringDB(create=True).commit()
|
||||
|
||||
try:
|
||||
backend.common.init_bringdb()
|
||||
except bringrss.exceptions.NoClosestBringDB as exc:
|
||||
log.error(exc.error_message)
|
||||
log.error('Try adding --init to create the database.')
|
||||
return 1
|
||||
|
||||
message = f'Starting server on port {port}, pid={os.getpid()}.'
|
||||
if use_https:
|
||||
message += ' (https)'
|
||||
log.info(message)
|
||||
|
||||
backend.common.start_background_threads()
|
||||
|
||||
try:
|
||||
http.serve_forever()
|
||||
except KeyboardInterrupt:
|
||||
log.info('Goodbye')
|
||||
return 0
|
||||
|
||||
def bringrss_flask_dev_argparse(args):
|
||||
return bringrss_flask_dev(
|
||||
demo_mode=args.demo_mode,
|
||||
localhost_only=args.localhost_only,
|
||||
init=args.init,
|
||||
port=args.port,
|
||||
use_https=args.use_https,
|
||||
)
|
||||
|
||||
@operatornotify.main_decorator(subject='bringrss_flask_dev', notify_every_line=True)
|
||||
@vlogging.main_decorator
|
||||
def main(argv):
|
||||
parser = argparse.ArgumentParser(
|
||||
description='''
|
||||
This file is the gevent launcher for local / development use.
|
||||
''',
|
||||
)
|
||||
parser.add_argument(
|
||||
'port',
|
||||
nargs='?',
|
||||
type=int,
|
||||
default=27464,
|
||||
help='''
|
||||
Port number on which to run the server.
|
||||
''',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--https',
|
||||
dest='use_https',
|
||||
action='store_true',
|
||||
help='''
|
||||
If this flag is not passed, HTTPS will automatically be enabled if the
|
||||
port is 443. You can pass this flag to enable HTTPS on other ports.
|
||||
We expect to find bringrss.key and bringrss.crt in
|
||||
frontends/bringrss_flask/https.
|
||||
''',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--demo_mode',
|
||||
'--demo-mode',
|
||||
action='store_true',
|
||||
help='''
|
||||
If this flag is passed, the server operates in demo mode, which means
|
||||
absolutely nothing can make modifications to the database and it is safe
|
||||
to present to the world.
|
||||
''',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--init',
|
||||
action='store_true',
|
||||
help='''
|
||||
Create a new BringRSS database in the current folder. If this is your
|
||||
first time running the server, you should include this.
|
||||
''',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--localhost_only',
|
||||
'--localhost-only',
|
||||
action='store_true',
|
||||
help='''
|
||||
If this flag is passed, only localhost will be able to access the server.
|
||||
Other users on the LAN will be blocked.
|
||||
''',
|
||||
)
|
||||
parser.set_defaults(func=bringrss_flask_dev_argparse)
|
||||
|
||||
return betterhelp.go(parser, argv)
|
||||
|
||||
if __name__ == '__main__':
|
||||
raise SystemExit(main(sys.argv[1:]))
|
||||
24
frontends/bringrss_flask/bringrss_flask_prod.py
Normal file
24
frontends/bringrss_flask/bringrss_flask_prod.py
Normal file
|
|
@ -0,0 +1,24 @@
|
|||
'''
|
||||
This file is the WSGI entrypoint for remote / production use.
|
||||
|
||||
If you are using Gunicorn, for example:
|
||||
gunicorn bringrss_flask_prod:site --bind "0.0.0.0:PORT" --access-logfile "-"
|
||||
'''
|
||||
import werkzeug.middleware.proxy_fix
|
||||
import os
|
||||
|
||||
from voussoirkit import pipeable
|
||||
|
||||
from bringrss_flask import backend
|
||||
|
||||
backend.site.wsgi_app = werkzeug.middleware.proxy_fix.ProxyFix(backend.site.wsgi_app)
|
||||
|
||||
site = backend.site
|
||||
site.debug = False
|
||||
|
||||
if os.environ.get('BRINGRSS_DEMO_MODE', False):
|
||||
pipeable.stderr('Setting demo_mode = True')
|
||||
site.demo_mode = True
|
||||
|
||||
backend.common.init_bringdb()
|
||||
backend.common.start_background_threads()
|
||||
BIN
frontends/bringrss_flask/static/basic_icons/folder.png
Normal file
BIN
frontends/bringrss_flask/static/basic_icons/folder.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 673 B |
73
frontends/bringrss_flask/static/basic_icons/folder.svg
Normal file
73
frontends/bringrss_flask/static/basic_icons/folder.svg
Normal file
{kind=link}
|
|
@ -0,0 +1,73 @@
|
|||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<!-- Created with Inkscape (http://www.inkscape.org/) -->
|
||||
|
||||
<svg
|
||||
xmlns:dc="http://purl.org/dc/elements/1.1/"
|
||||
xmlns:cc="http://creativecommons.org/ns#"
|
||||
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
|
||||
xmlns:svg="http://www.w3.org/2000/svg"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
|
||||
xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
|
||||
width="32"
|
||||
height="32"
|
||||
viewBox="0 0 8.4666665 8.4666669"
|
||||
version="1.1"
|
||||
id="svg8"
|
||||
inkscape:version="0.92.3 (2405546, 2018-03-11)"
|
||||
sodipodi:docname="folder.svg"
|
||||
inkscape:export-filename="D:\Git\bringrss\frontends\bringrss_flask\static\basic_icons\folder.png"
|
||||
inkscape:export-xdpi="96.000008"
|
||||
inkscape:export-ydpi="96.000008">
|
||||
<defs
|
||||
id="defs2" />
|
||||
<sodipodi:namedview
|
||||
id="base"
|
||||
pagecolor="#ffffff"
|
||||
bordercolor="#666666"
|
||||
borderopacity="1.0"
|
||||
inkscape:pageopacity="0.0"
|
||||
inkscape:pageshadow="2"
|
||||
inkscape:zoom="16"
|
||||
inkscape:cx="16.792735"
|
||||
inkscape:cy="18.415996"
|
||||
inkscape:document-units="mm"
|
||||
inkscape:current-layer="layer1"
|
||||
showgrid="false"
|
||||
units="px"
|
||||
inkscape:window-width="1920"
|
||||
inkscape:window-height="1019"
|
||||
inkscape:window-x="-8"
|
||||
inkscape:window-y="-8"
|
||||
inkscape:window-maximized="1" />
|
||||
<metadata
|
||||
id="metadata5">
|
||||
<rdf:RDF>
|
||||
<cc:Work
|
||||
rdf:about="">
|
||||
<dc:format>image/svg+xml</dc:format>
|
||||
<dc:type
|
||||
rdf:resource="http://purl.org/dc/dcmitype/StillImage" />
|
||||
<dc:title></dc:title>
|
||||
</cc:Work>
|
||||
</rdf:RDF>
|
||||
</metadata>
|
||||
<g
|
||||
inkscape:label="Layer 1"
|
||||
inkscape:groupmode="layer"
|
||||
id="layer1"
|
||||
transform="translate(0,-288.53332)">
|
||||
<path
|
||||
sodipodi:nodetypes="ccccc"
|
||||
inkscape:connector-curvature="0"
|
||||
id="path4520"
|
||||
d="M 0.9517787,294.97413 0.68116834,290.55917 H 6.3439413 l 0.2706104,4.41496 z"
|
||||
style="opacity:1;fill:#b8b630;fill-opacity:1;stroke:#000000;stroke-width:1;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;paint-order:stroke fill markers" />
|
||||
<path
|
||||
style="opacity:1;fill:#fffd85;fill-opacity:1;stroke:#000000;stroke-width:1;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;paint-order:stroke fill markers"
|
||||
d="m 1.1171433,294.97413 0.9204179,-3.14042 h 5.662773 l -0.9204179,3.14042 z"
|
||||
id="path4518"
|
||||
inkscape:connector-curvature="0"
|
||||
sodipodi:nodetypes="ccccc" />
|
||||
</g>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 2.6 KiB |
BIN
frontends/bringrss_flask/static/basic_icons/rss.png
Normal file
BIN
frontends/bringrss_flask/static/basic_icons/rss.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 1.3 KiB |
15
frontends/bringrss_flask/static/css/bringrss.css
Normal file
15
frontends/bringrss_flask/static/css/bringrss.css
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
body
|
||||
{
|
||||
font-family: sans-serif;
|
||||
font-size: 10pt;
|
||||
max-height: 100%;
|
||||
}
|
||||
|
||||
p:first-child
|
||||
{
|
||||
margin-top: 0;
|
||||
}
|
||||
p:last-child
|
||||
{
|
||||
margin-bottom: 0;
|
||||
}
|
||||
263
frontends/bringrss_flask/static/css/common.css
Normal file
263
frontends/bringrss_flask/static/css/common.css
Normal file
|
|
@ -0,0 +1,263 @@
|
|||
/*
|
||||
This file contains styles that I want on almost all webpages that I make,
|
||||
not specific to one project.
|
||||
*/
|
||||
|
||||
/*
|
||||
These properties are used by javascript functions in common.js.
|
||||
See common.is_narrow_mode, is_wide_mode.
|
||||
getComputedStyle(document.documentElement).getPropertyValue("--narrow").trim() === "1"
|
||||
*/
|
||||
@media screen and (min-width: 800px)
|
||||
{
|
||||
:root
|
||||
{
|
||||
--wide: 1;
|
||||
}
|
||||
}
|
||||
@media screen and (max-width: 800px)
|
||||
{
|
||||
:root
|
||||
{
|
||||
--narrow: 1;
|
||||
}
|
||||
}
|
||||
|
||||
html
|
||||
{
|
||||
height: 100vh;
|
||||
box-sizing: border-box;
|
||||
color: var(--color_text_normal);
|
||||
}
|
||||
|
||||
*, *:before, *:after
|
||||
{
|
||||
box-sizing: inherit;
|
||||
color: inherit;
|
||||
}
|
||||
|
||||
body
|
||||
{
|
||||
display: grid;
|
||||
grid-template:
|
||||
"header" auto
|
||||
"content_body" 1fr
|
||||
/1fr;
|
||||
|
||||
min-height: 100%;
|
||||
margin: 0;
|
||||
|
||||
background-color: var(--color_primary);
|
||||
}
|
||||
|
||||
a
|
||||
{
|
||||
color: var(--color_text_link);
|
||||
cursor: pointer;
|
||||
}
|
||||
|
||||
input, select, textarea
|
||||
{
|
||||
background-color: var(--color_textfields);
|
||||
}
|
||||
|
||||
input:disabled,
|
||||
select:disabled,
|
||||
textarea:disabled
|
||||
{
|
||||
background-color: var(--color_text_placeholder);
|
||||
}
|
||||
|
||||
input::placeholder, textarea::placeholder
|
||||
{
|
||||
color: var(--color_text_placeholder);
|
||||
opacity: 1;
|
||||
}
|
||||
|
||||
pre
|
||||
{
|
||||
white-space: pre-line;
|
||||
}
|
||||
|
||||
.hidden
|
||||
{
|
||||
display: none !important;
|
||||
}
|
||||
|
||||
.bold
|
||||
{
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
#header
|
||||
{
|
||||
grid-area: header;
|
||||
display: flex;
|
||||
flex-direction: row;
|
||||
|
||||
height: 18px;
|
||||
margin: 8px;
|
||||
margin-bottom: 0;
|
||||
background-color: var(--color_transparency);
|
||||
}
|
||||
#header button
|
||||
{
|
||||
border: 0;
|
||||
cursor: pointer;
|
||||
background-color: transparent;
|
||||
}
|
||||
.header_element
|
||||
{
|
||||
flex: 1;
|
||||
display: flex;
|
||||
justify-content: center;
|
||||
}
|
||||
.header_element:hover
|
||||
{
|
||||
background-color: var(--color_transparency);
|
||||
}
|
||||
|
||||
#content_body
|
||||
{
|
||||
grid-area: content_body;
|
||||
display: grid;
|
||||
grid-auto-rows: min-content;
|
||||
grid-gap: 8px;
|
||||
|
||||
padding: 8px;
|
||||
}
|
||||
|
||||
.panel
|
||||
{
|
||||
background-color: var(--color_transparency);
|
||||
border-radius: 5px;
|
||||
padding: 8px;
|
||||
}
|
||||
|
||||
button,
|
||||
button *
|
||||
{
|
||||
color: var(--color_text_normal);
|
||||
}
|
||||
button:disabled
|
||||
{
|
||||
background-color: #cccccc !important;
|
||||
}
|
||||
button
|
||||
{
|
||||
border-top: 2px solid var(--color_highlight);
|
||||
border-left: 2px solid var(--color_highlight);
|
||||
border-right: 2px solid var(--color_shadow);
|
||||
border-bottom: 2px solid var(--color_shadow);
|
||||
}
|
||||
button:active
|
||||
{
|
||||
border-top: 2px solid var(--color_shadow);
|
||||
border-left: 2px solid var(--color_shadow);
|
||||
border-right: 2px solid var(--color_highlight);
|
||||
border-bottom: 2px solid var(--color_highlight);
|
||||
}
|
||||
.gray_button
|
||||
{
|
||||
background-color: #cccccc;
|
||||
}
|
||||
.green_button
|
||||
{
|
||||
background-color: #6df16f;
|
||||
}
|
||||
.red_button
|
||||
{
|
||||
background-color: #ff4949;
|
||||
}
|
||||
.yellow_button
|
||||
{
|
||||
background-color: #ffea57;
|
||||
}
|
||||
|
||||
.tabbed_container
|
||||
{
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
}
|
||||
.tabbed_container .tab_buttons
|
||||
{
|
||||
display: flex;
|
||||
flex-direction: row;
|
||||
flex-wrap: wrap;
|
||||
}
|
||||
.tabbed_container .tab_button
|
||||
{
|
||||
/* outline: none; prevents the blue outline left after clicking on it */
|
||||
outline: none;
|
||||
flex: 1;
|
||||
font-family: inherit;
|
||||
font-size: 1.3em;
|
||||
border-radius: 8px 8px 0 0;
|
||||
background-color: transparent;
|
||||
}
|
||||
.tabbed_container .tab_button:hover
|
||||
{
|
||||
background-color: var(--color_transparency);
|
||||
}
|
||||
.tabbed_container .tab,
|
||||
.tabbed_container .tab_button
|
||||
{
|
||||
border-width: 2px;
|
||||
border-style: solid;
|
||||
border-color: #888;
|
||||
}
|
||||
.tabbed_container .tab_button.tab_button_inactive
|
||||
{
|
||||
border-top-color: transparent;
|
||||
border-left-color: transparent;
|
||||
border-right-color: transparent;
|
||||
}
|
||||
.tabbed_container .tab_button.tab_button_active
|
||||
{
|
||||
background-color: var(--color_transparency);
|
||||
border-bottom-color: transparent;
|
||||
}
|
||||
.tabbed_container .tab
|
||||
{
|
||||
/* This will be set by javascript after the tabs have been initialized.
|
||||
That way, the tab panes don't have a missing top border while the dom is
|
||||
loading or if javascript is disabled.
|
||||
/*border-top-color: transparent;*/
|
||||
}
|
||||
|
||||
#message_area
|
||||
{
|
||||
display: grid;
|
||||
grid-auto-flow: row;
|
||||
grid-auto-rows: min-content;
|
||||
grid-gap: 8px;
|
||||
padding: 8px;
|
||||
overflow-y: auto;
|
||||
background-color: var(--color_transparency);
|
||||
}
|
||||
#message_area > :last-child
|
||||
{
|
||||
/*
|
||||
For some reason, the message_area's 8px padding doesn't apply to the bottom
|
||||
when the container is scrolled.
|
||||
*/
|
||||
margin-bottom: 8px;
|
||||
}
|
||||
|
||||
.message_bubble
|
||||
{
|
||||
padding: 2px;
|
||||
word-wrap: break-word;
|
||||
}
|
||||
.message_bubble *
|
||||
{
|
||||
color: var(--color_text_bubble);
|
||||
}
|
||||
.message_positive
|
||||
{
|
||||
background-color: #afa;
|
||||
}
|
||||
.message_negative
|
||||
{
|
||||
background-color: #faa;
|
||||
}
|
||||
33
frontends/bringrss_flask/static/css/theme_onyx.css
Normal file
33
frontends/bringrss_flask/static/css/theme_onyx.css
Normal file
|
|
@ -0,0 +1,33 @@
|
|||
:root
|
||||
{
|
||||
--color_primary: #000;
|
||||
--color_secondary: #3b4d5d;
|
||||
|
||||
--color_text_normal: #ccc;
|
||||
--color_text_link: #1edeff;
|
||||
--color_text_bubble: black;
|
||||
|
||||
--color_textfields: var(--color_primary);
|
||||
--color_text_placeholder: gray;
|
||||
|
||||
--color_selection: rgba(0, 0, 255, 0.5);
|
||||
--color_transparency: rgba(0, 0, 0, 0.0);
|
||||
--color_dropshadow: rgba(0, 0, 0, 0.25);
|
||||
--color_shadow: rgba(0, 0, 0, 0.5);
|
||||
--color_highlight: rgba(255, 255, 255, 0.5);
|
||||
}
|
||||
|
||||
button,
|
||||
button *
|
||||
{
|
||||
color: black;
|
||||
}
|
||||
|
||||
input,
|
||||
textarea,
|
||||
#filters .filter,
|
||||
.nice_link,
|
||||
.panel
|
||||
{
|
||||
border: 1px solid var(--color_text_normal);
|
||||
}
|
||||
21
frontends/bringrss_flask/static/css/theme_pearl.css
Normal file
21
frontends/bringrss_flask/static/css/theme_pearl.css
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
:root
|
||||
{
|
||||
--color_primary: #f6ffff;
|
||||
--color_secondary: #aad7ff;
|
||||
|
||||
--color_text_normal: black;
|
||||
--color_text_link: #00f;
|
||||
--color_text_bubble: black;
|
||||
|
||||
--color_textfields: white;
|
||||
--color_text_placeholder: gray;
|
||||
|
||||
--color_selection: rgba(229, 126, 200, 0.7);
|
||||
--color_transparency: rgba(0, 0, 0, 0.1);
|
||||
--color_dropshadow: rgba(0, 0, 0, 0.25);
|
||||
--color_shadow: rgba(0, 0, 0, 0.5);
|
||||
--color_highlight: rgba(255, 255, 255, 0.5);
|
||||
|
||||
--color_tag_card_bg: #fff;
|
||||
--color_tag_card_fg: black;
|
||||
}
|
||||
24
frontends/bringrss_flask/static/css/theme_slate.css
Normal file
24
frontends/bringrss_flask/static/css/theme_slate.css
Normal file
|
|
@ -0,0 +1,24 @@
|
|||
:root
|
||||
{
|
||||
--color_primary: #222;
|
||||
--color_secondary: #3b4d5d;
|
||||
|
||||
--color_text_normal: #efefef;
|
||||
--color_text_link: #1edeff;
|
||||
--color_text_bubble: black;
|
||||
|
||||
--color_textfields: var(--color_secondary);
|
||||
--color_text_placeholder: gray;
|
||||
|
||||
--color_selection: rgba(0, 0, 255, 0.5);
|
||||
--color_transparency: rgba(255, 255, 255, 0.05);
|
||||
--color_dropshadow: rgba(0, 0, 0, 0.25);
|
||||
--color_shadow: rgba(0, 0, 0, 0.5);
|
||||
--color_highlight: rgba(255, 255, 255, 0.5);
|
||||
}
|
||||
|
||||
button,
|
||||
button *
|
||||
{
|
||||
color: black;
|
||||
}
|
||||
21
frontends/bringrss_flask/static/css/theme_turquoise.css
Normal file
21
frontends/bringrss_flask/static/css/theme_turquoise.css
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
:root
|
||||
{
|
||||
--color_primary: #00d8f4;
|
||||
--color_secondary: #ffffd4;
|
||||
|
||||
--color_text_normal: black;
|
||||
--color_text_link: blue;
|
||||
--color_text_bubble: black;
|
||||
|
||||
--color_textfields: white;
|
||||
--color_text_placeholder: gray;
|
||||
|
||||
--color_selection: rgba(255, 255, 212, 0.7);
|
||||
--color_transparency: rgba(0, 0, 0, 0.1);
|
||||
--color_dropshadow: rgba(0, 0, 0, 0.25);
|
||||
--color_shadow: rgba(0, 0, 0, 0.5);
|
||||
--color_highlight: rgba(255, 255, 255, 0.5);
|
||||
|
||||
--color_tag_card_bg: #fff;
|
||||
--color_tag_card_fg: blue;
|
||||
}
|
||||
BIN
frontends/bringrss_flask/static/favicon.png
Normal file
BIN
frontends/bringrss_flask/static/favicon.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 1.4 KiB |
267
frontends/bringrss_flask/static/js/api.js
Normal file
267
frontends/bringrss_flask/static/js/api.js
Normal file
|
|
@ -0,0 +1,267 @@
|
|||
const api = {};
|
||||
|
||||
/**************************************************************************************************/
|
||||
api.feeds = {};
|
||||
|
||||
api.feeds.add_feed =
|
||||
function add_feed(rss_url, title, isolate_guids, callback)
|
||||
{
|
||||
const url = "/feeds/add";
|
||||
const data = {"rss_url": rss_url, "title": title, "isolate_guids": isolate_guids};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.delete =
|
||||
function delete_feed(feed_id, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/delete`;
|
||||
return common.post(url, null, callback);
|
||||
}
|
||||
|
||||
api.feeds.get_feeds =
|
||||
function get_feeds(callback)
|
||||
{
|
||||
const url = "/feeds.json";
|
||||
return common.get(url, callback);
|
||||
}
|
||||
|
||||
api.feeds.refresh =
|
||||
function refresh(feed_id, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/refresh`;
|
||||
return common.post(url, null, callback);
|
||||
}
|
||||
|
||||
api.feeds.refresh_all =
|
||||
function refresh_all(callback)
|
||||
{
|
||||
const url = "/feeds/refresh_all";
|
||||
return common.post(url, null, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_autorefresh_interval =
|
||||
function set_autorefresh_interval(feed_id, interval, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_autorefresh_interval`;
|
||||
const data = {"autorefresh_interval": interval};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_filters =
|
||||
function set_filters(feed_id, filter_ids, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_filters`;
|
||||
const data = {"filter_ids": filter_ids.join(",")};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_http_headers =
|
||||
function set_http_headers(feed_id, http_headers, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_http_headers`;
|
||||
const data = {"http_headers": http_headers};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_icon =
|
||||
function set_icon(feed_id, image_base64, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_icon`;
|
||||
const data = {"image_base64": image_base64};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_isolate_guids =
|
||||
function set_isolate_guids(feed_id, isolate_guids, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_isolate_guids`;
|
||||
const data = {"isolate_guids": isolate_guids};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_parent =
|
||||
function set_parent(feed_id, parent_id, ui_order_rank, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_parent`;
|
||||
const data = {"parent_id": parent_id};
|
||||
if (ui_order_rank !== null)
|
||||
{
|
||||
data["ui_order_rank"] = ui_order_rank;
|
||||
}
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_refresh_with_others =
|
||||
function set_refresh_with_others(feed_id, refresh_with_others, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_refresh_with_others`;
|
||||
const data = {"refresh_with_others": refresh_with_others};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_rss_url =
|
||||
function set_rss_url(feed_id, rss_url, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_rss_url`;
|
||||
const data = {"rss_url": rss_url};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_web_url =
|
||||
function set_web_url(feed_id, web_url, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_web_url`;
|
||||
const data = {"web_url": web_url};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_title =
|
||||
function set_title(feed_id, title, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_title`;
|
||||
const data = {"title": title};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.feeds.set_ui_order_rank =
|
||||
function set_ui_order_rank(feed_id, ui_order_rank, callback)
|
||||
{
|
||||
const url = `/feed/${feed_id}/set_ui_order_rank`;
|
||||
const data = {"ui_order_rank": ui_order_rank};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
/**************************************************************************************************/
|
||||
api.filters = {};
|
||||
|
||||
api.filters.add_filter =
|
||||
function add_filter(name, conditions, actions, callback)
|
||||
{
|
||||
const url = "/filters/add";
|
||||
const data = {"name": name, "conditions": conditions, "actions": actions};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.filters.delete_filter =
|
||||
function delete_filter(filter_id, callback)
|
||||
{
|
||||
const url = `/filter/${filter_id}/delete`;
|
||||
return common.post(url, null, callback);
|
||||
}
|
||||
|
||||
api.filters.get_filters =
|
||||
function get_filters(callback)
|
||||
{
|
||||
const url = "/filters.json";
|
||||
return common.get(url, callback);
|
||||
}
|
||||
|
||||
api.filters.run_filter_now =
|
||||
function run_filter_now(filter_id, feed_id, callback)
|
||||
{
|
||||
const url = `/filter/${filter_id}/run_filter`;
|
||||
const data = {};
|
||||
if (feed_id !== null)
|
||||
{
|
||||
data['feed_id'] = feed_id;
|
||||
}
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.filters.set_actions =
|
||||
function set_actions(filter_id, actions, callback)
|
||||
{
|
||||
const url = `/filter/${filter_id}/set_actions`;
|
||||
const data = {"actions": actions};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.filters.set_conditions =
|
||||
function set_conditions(filter_id, conditions, callback)
|
||||
{
|
||||
const url = `/filter/${filter_id}/set_conditions`;
|
||||
const data = {"conditions": conditions};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.filters.set_name =
|
||||
function set_name(filter_id, name, callback)
|
||||
{
|
||||
const url = `/filter/${filter_id}/set_name`;
|
||||
const data = {"name": name};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.filters.update_filter =
|
||||
function update_filter(filter_id, name, conditions, actions, callback)
|
||||
{
|
||||
const url = `/filter/${filter_id}/update`;
|
||||
const data = {"name": name, "conditions": conditions, "actions": actions};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
/**************************************************************************************************/
|
||||
api.news = {};
|
||||
|
||||
api.news.get_and_set_read =
|
||||
function get_and_set_read(news_id, callback)
|
||||
{
|
||||
const url = `/news/${news_id}.json`;
|
||||
const data = {"set_read": true};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.news.get_newss =
|
||||
function get_newss(feed_id, read, recycled, callback)
|
||||
{
|
||||
let parameters = new URLSearchParams();
|
||||
if (read !== null)
|
||||
{
|
||||
parameters.set("read", read);
|
||||
}
|
||||
if (recycled !== null)
|
||||
{
|
||||
parameters.set("recycled", recycled);
|
||||
}
|
||||
parameters = parameters.toString();
|
||||
if (parameters !== "")
|
||||
{
|
||||
parameters = "?" + parameters;
|
||||
}
|
||||
let url = (feed_id === null) ? "/news.json" : `/feed/${feed_id}/news.json`;
|
||||
url += parameters;
|
||||
return common.get(url, callback);
|
||||
|
||||
}
|
||||
|
||||
api.news.set_read =
|
||||
function set_read(news_id, read, callback)
|
||||
{
|
||||
const url = `/news/${news_id}/set_read`;
|
||||
const data = {"read": read};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.news.set_recycled =
|
||||
function set_recycled(news_id, recycled, callback)
|
||||
{
|
||||
const url = `/news/${news_id}/set_recycled`;
|
||||
const data = {"recycled": recycled};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.news.batch_set_read =
|
||||
function batch_set_read(news_ids, read, callback)
|
||||
{
|
||||
const url = `/batch/news/set_read`;
|
||||
const data = {"news_ids": news_ids.join(","), "read": read};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
|
||||
api.news.batch_set_recycled =
|
||||
function batch_set_recycled(news_ids, recycled, callback)
|
||||
{
|
||||
const url = `/batch/news/set_recycled`;
|
||||
const data = {"news_ids": news_ids.join(","), "recycled": recycled};
|
||||
return common.post(url, data, callback);
|
||||
}
|
||||
697
frontends/bringrss_flask/static/js/common.js
Normal file
697
frontends/bringrss_flask/static/js/common.js
Normal file
|
|
@ -0,0 +1,697 @@
|
|||
const common = {};
|
||||
|
||||
common.INPUT_TYPES = new Set(["INPUT", "TEXTAREA"]);
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
// UTILS ///////////////////////////////////////////////////////////////////////////////////////////
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.create_message_bubble =
|
||||
function create_message_bubble(message_area, message_positivity, message_text, lifespan)
|
||||
{
|
||||
if (lifespan === undefined)
|
||||
{
|
||||
lifespan = 8000;
|
||||
}
|
||||
const message = document.createElement("div");
|
||||
message.className = "message_bubble " + message_positivity;
|
||||
const span = document.createElement("span");
|
||||
span.innerHTML = message_text;
|
||||
message.appendChild(span);
|
||||
message_area.appendChild(message);
|
||||
setTimeout(function(){message_area.removeChild(message);}, lifespan);
|
||||
}
|
||||
|
||||
common.is_narrow_mode =
|
||||
function is_narrow_mode()
|
||||
{
|
||||
return getComputedStyle(document.documentElement).getPropertyValue("--narrow").trim() === "1";
|
||||
}
|
||||
|
||||
common.is_wide_mode =
|
||||
function is_wide_mode()
|
||||
{
|
||||
return getComputedStyle(document.documentElement).getPropertyValue("--wide").trim() === "1";
|
||||
}
|
||||
|
||||
common.refresh =
|
||||
function refresh()
|
||||
{
|
||||
window.location.reload();
|
||||
}
|
||||
|
||||
common.refresh_or_alert =
|
||||
function refresh_or_alert(response)
|
||||
{
|
||||
if (response.meta.status !== 200)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
window.location.reload();
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
// HTTP ////////////////////////////////////////////////////////////////////////////////////////////
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.formdata =
|
||||
function formdata(data)
|
||||
{
|
||||
fd = new FormData();
|
||||
for (let [key, value] of Object.entries(data))
|
||||
{
|
||||
if (value === undefined)
|
||||
{
|
||||
continue;
|
||||
}
|
||||
if (value === null)
|
||||
{
|
||||
value = '';
|
||||
}
|
||||
fd.append(key, value);
|
||||
}
|
||||
return fd;
|
||||
}
|
||||
|
||||
common._request =
|
||||
function _request(method, url, callback)
|
||||
{
|
||||
/*
|
||||
Perform an HTTP request and call the `callback` with the response.
|
||||
|
||||
The response will have the following structure:
|
||||
{
|
||||
"meta": {
|
||||
"completed": true / false,
|
||||
"status": If the connection failed or request otherwise could not
|
||||
complete, `status` will be 0. If the request completed,
|
||||
`status` will be the HTTP response code.
|
||||
"json_ok": If the server responded with parseable json, `json_ok`
|
||||
will be true, and that data will be in `response.data`. If the
|
||||
server response was not parseable json, `json_ok` will be false
|
||||
and `response.data` will be undefined.
|
||||
"request_url": The URL exactly as given to this call.
|
||||
}
|
||||
"data": {JSON parsed from server response if json_ok}.
|
||||
}
|
||||
|
||||
So, from most lenient to most strict, error catching might look like:
|
||||
if response.meta.completed
|
||||
if response.meta.json_ok
|
||||
if response.meta.status === 200
|
||||
if response.meta.status === 200 and response.meta.json_ok
|
||||
*/
|
||||
const request = new XMLHttpRequest();
|
||||
const response = {
|
||||
"meta": {
|
||||
"completed": false,
|
||||
"status": 0,
|
||||
"json_ok": false,
|
||||
"request_url": url,
|
||||
},
|
||||
};
|
||||
|
||||
request.onreadystatechange = function()
|
||||
{
|
||||
/*
|
||||
readystate values:
|
||||
0 UNSENT / ABORTED
|
||||
1 OPENED
|
||||
2 HEADERS_RECEIVED
|
||||
3 LOADING
|
||||
4 DONE
|
||||
*/
|
||||
if (request.readyState != 4)
|
||||
{return;}
|
||||
|
||||
if (callback == null)
|
||||
{return;}
|
||||
|
||||
response.meta.status = request.status;
|
||||
|
||||
if (request.status != 0)
|
||||
{
|
||||
response.meta.completed = true;
|
||||
try
|
||||
{
|
||||
response.data = JSON.parse(request.responseText);
|
||||
response.meta.json_ok = true;
|
||||
}
|
||||
catch (exc)
|
||||
{
|
||||
response.meta.json_ok = false;
|
||||
}
|
||||
}
|
||||
callback(response);
|
||||
};
|
||||
const asynchronous = true;
|
||||
request.open(method, url, asynchronous);
|
||||
return request;
|
||||
}
|
||||
|
||||
common.get =
|
||||
function get(url, callback)
|
||||
{
|
||||
request = common._request("GET", url, callback);
|
||||
request.send();
|
||||
return request;
|
||||
}
|
||||
|
||||
common.post =
|
||||
function post(url, data, callback)
|
||||
{
|
||||
/*
|
||||
`data`:
|
||||
a FormData object which you have already filled with values, or a
|
||||
dictionary from which a FormData will be made, using common.formdata.
|
||||
*/
|
||||
if (data instanceof FormData || data === null)
|
||||
{
|
||||
;
|
||||
}
|
||||
else
|
||||
{
|
||||
data = common.formdata(data);
|
||||
}
|
||||
request = common._request("POST", url, callback);
|
||||
request.send(data);
|
||||
return request;
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
// STRING TOOLS ////////////////////////////////////////////////////////////////////////////////////
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.join_and_trail =
|
||||
function join_and_trail(l, s)
|
||||
{
|
||||
if (l.length === 0)
|
||||
{
|
||||
return "";
|
||||
}
|
||||
return l.join(s) + s
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
// HTML & DOM //////////////////////////////////////////////////////////////////////////////////////
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.delete_all_children =
|
||||
function delete_all_children(element)
|
||||
{
|
||||
while (element.firstChild)
|
||||
{
|
||||
element.removeChild(element.firstChild);
|
||||
}
|
||||
}
|
||||
|
||||
common.html_to_element =
|
||||
function html_to_element(html)
|
||||
{
|
||||
const template = document.createElement("template");
|
||||
template.innerHTML = html.trim();
|
||||
return template.content.firstElementChild;
|
||||
}
|
||||
|
||||
common.size_iframe_to_content =
|
||||
function size_iframe_to_content(iframe)
|
||||
{
|
||||
iframe.style.height = iframe.contentWindow.document.documentElement.scrollHeight + 'px';
|
||||
}
|
||||
|
||||
common.update_dynamic_elements =
|
||||
function update_dynamic_elements(class_name, text)
|
||||
{
|
||||
/*
|
||||
Find all elements with this class and set their innertext to this text.
|
||||
*/
|
||||
const elements = document.getElementsByClassName(class_name);
|
||||
for (const element of elements)
|
||||
{
|
||||
element.innerText = text;
|
||||
}
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
// HOOKS & ADD-ONS /////////////////////////////////////////////////////////////////////////////////
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.bind_box_to_button =
|
||||
function bind_box_to_button(box, button, ctrl_enter)
|
||||
{
|
||||
/*
|
||||
Bind a textbox to a button so that pressing Enter within the textbox is the
|
||||
same as clicking the button.
|
||||
|
||||
If `ctrl_enter` is true, then you must press ctrl+Enter to trigger the
|
||||
button, which is important for textareas.
|
||||
|
||||
Thanks Yaroslav Yakovlev
|
||||
http://stackoverflow.com/a/9343095
|
||||
*/
|
||||
const bound_box_hook = function(event)
|
||||
{
|
||||
if (event.key !== "Enter")
|
||||
{return;}
|
||||
|
||||
ctrl_success = !ctrl_enter || (event.ctrlKey);
|
||||
|
||||
if (! ctrl_success)
|
||||
{return;}
|
||||
|
||||
button.click();
|
||||
}
|
||||
box.addEventListener("keyup", bound_box_hook);
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
// CSS-JS CLASSES //////////////////////////////////////////////////////////////////////////////////
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.init_atag_merge_params =
|
||||
function init_atag_merge_params(a)
|
||||
{
|
||||
/*
|
||||
To create an <a> tag where the ?parameters written on the href are merged
|
||||
with the parameters of the current page URL, give it the class
|
||||
"merge_params". If the URL and href contain the same parameter, the href
|
||||
takes priority.
|
||||
|
||||
Optional:
|
||||
data-merge-params: A whitelist of parameter names, separated by commas
|
||||
or spaces. Only these parameters will be merged from the page URL.
|
||||
|
||||
data-merge-params-except: A blacklist of parameter names, separated by
|
||||
commas or spaces. All parameters except these will be merged from
|
||||
the page URL.
|
||||
|
||||
Example:
|
||||
URL: ?filter=hello&orderby=score
|
||||
href: "?orderby=date"
|
||||
Result: "?filter=hello&orderby=date"
|
||||
*/
|
||||
const page_params = Array.from(new URLSearchParams(window.location.search));
|
||||
let to_merge;
|
||||
|
||||
if (a.dataset.mergeParams)
|
||||
{
|
||||
const keep = new Set(a.dataset.mergeParams.split(/[\s,]+/));
|
||||
to_merge = page_params.filter(key_value => keep.has(key_value[0]));
|
||||
delete a.dataset.mergeParams;
|
||||
}
|
||||
else if (a.dataset.mergeParamsExcept)
|
||||
{
|
||||
const remove = new Set(a.dataset.mergeParamsExcept.split(/[\s,]+/));
|
||||
to_merge = page_params.filter(key_value => (! remove.has(key_value[0])));
|
||||
delete a.dataset.mergeParamsExcept;
|
||||
}
|
||||
else
|
||||
{
|
||||
to_merge = page_params;
|
||||
}
|
||||
|
||||
to_merge = to_merge.concat(Array.from(new URLSearchParams(a.search)));
|
||||
const new_params = new URLSearchParams();
|
||||
for (const [key, value] of to_merge)
|
||||
{ new_params.set(key, value); }
|
||||
a.search = new_params.toString();
|
||||
a.classList.remove("merge_params");
|
||||
}
|
||||
|
||||
common.init_all_atag_merge_params =
|
||||
function init_all_atag_merge_params()
|
||||
{
|
||||
const page_params = Array.from(new URLSearchParams(window.location.search));
|
||||
const as = Array.from(document.getElementsByClassName("merge_params"));
|
||||
for (const a of as)
|
||||
{
|
||||
setTimeout(() => common.init_atag_merge_params(a), 0);
|
||||
}
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.init_button_with_confirm =
|
||||
function init_button_with_confirm(button)
|
||||
{
|
||||
/*
|
||||
To create a button that requires a second confirmation step, assign it the
|
||||
class "button_with_confirm".
|
||||
|
||||
Required:
|
||||
data-onclick: String that would normally be the button's onclick.
|
||||
This is done so that if the button_with_confirm fails to initialize,
|
||||
the button will be non-operational as opposed to being operational
|
||||
but with no confirmation. For dangerous actions I think this is a
|
||||
worthwhile move though it could lead to feature downtime.
|
||||
|
||||
Optional:
|
||||
data-prompt: Text that appears next to the confirm button. Default is
|
||||
"Are you sure?".
|
||||
|
||||
data-prompt-class: CSS class for the prompt span.
|
||||
|
||||
data-confirm: Text inside the confirm button. Default is to inherit the
|
||||
original button's text.
|
||||
|
||||
data-confirm-class: CSS class for the confirm button. Default is to
|
||||
inheret all classes of the original button, except for
|
||||
"button_with_confirm" of course.
|
||||
|
||||
data-cancel: Text inside the cancel button. Default is "Cancel".
|
||||
|
||||
data-cancel-class: CSS class for the cancel button.
|
||||
|
||||
data-holder-class: CSS class for the new span that holds the menu.
|
||||
*/
|
||||
button.classList.remove("button_with_confirm");
|
||||
|
||||
const holder = document.createElement("span");
|
||||
holder.className = ("confirm_holder " + (button.dataset.holderClass || "")).trim();
|
||||
delete button.dataset.holderClass;
|
||||
if (button.dataset.holderId)
|
||||
{
|
||||
holder.id = button.dataset.holderId;
|
||||
delete button.dataset.holderId;
|
||||
}
|
||||
button.parentElement.insertBefore(holder, button);
|
||||
|
||||
const holder_stage1 = document.createElement("span");
|
||||
holder_stage1.className = "confirm_holder_stage1";
|
||||
holder_stage1.appendChild(button);
|
||||
holder.appendChild(holder_stage1);
|
||||
|
||||
const holder_stage2 = document.createElement("span");
|
||||
holder_stage2.className = "confirm_holder_stage2 hidden";
|
||||
holder.appendChild(holder_stage2);
|
||||
|
||||
let prompt;
|
||||
let input_source;
|
||||
if (button.dataset.isInput)
|
||||
{
|
||||
prompt = document.createElement("input");
|
||||
prompt.placeholder = button.dataset.prompt || "";
|
||||
input_source = prompt;
|
||||
}
|
||||
else
|
||||
{
|
||||
prompt = document.createElement("span");
|
||||
prompt.innerText = (button.dataset.prompt || "Are you sure?") + " ";
|
||||
input_source = undefined;
|
||||
}
|
||||
if (button.dataset.promptClass)
|
||||
{
|
||||
prompt.className = button.dataset.promptClass;
|
||||
}
|
||||
holder_stage2.appendChild(prompt)
|
||||
delete button.dataset.prompt;
|
||||
delete button.dataset.promptClass;
|
||||
|
||||
const button_confirm = document.createElement("button");
|
||||
button_confirm.innerText = (button.dataset.confirm || button.innerText).trim();
|
||||
if (button.dataset.confirmClass === undefined)
|
||||
{
|
||||
button_confirm.className = button.className;
|
||||
button_confirm.classList.remove("button_with_confirm");
|
||||
}
|
||||
else
|
||||
{
|
||||
button_confirm.className = button.dataset.confirmClass;
|
||||
}
|
||||
button_confirm.input_source = input_source;
|
||||
holder_stage2.appendChild(button_confirm);
|
||||
holder_stage2.appendChild(document.createTextNode(" "));
|
||||
if (button.dataset.isInput)
|
||||
{
|
||||
common.bind_box_to_button(prompt, button_confirm);
|
||||
}
|
||||
delete button.dataset.confirm;
|
||||
delete button.dataset.confirmClass;
|
||||
delete button.dataset.isInput;
|
||||
|
||||
const button_cancel = document.createElement("button");
|
||||
button_cancel.innerText = button.dataset.cancel || "Cancel";
|
||||
button_cancel.className = button.dataset.cancelClass || "";
|
||||
holder_stage2.appendChild(button_cancel);
|
||||
delete button.dataset.cancel;
|
||||
delete button.dataset.cancelClass;
|
||||
|
||||
// If this is stupid, let me know.
|
||||
const confirm_onclick = `
|
||||
let holder = event.target.parentElement.parentElement;
|
||||
holder.getElementsByClassName("confirm_holder_stage1")[0].classList.remove("hidden");
|
||||
holder.getElementsByClassName("confirm_holder_stage2")[0].classList.add("hidden");
|
||||
` + button.dataset.onclick;
|
||||
button_confirm.onclick = Function(confirm_onclick);
|
||||
|
||||
button.removeAttribute("onclick");
|
||||
button.onclick = function(event)
|
||||
{
|
||||
const holder = event.target.parentElement.parentElement;
|
||||
holder.getElementsByClassName("confirm_holder_stage1")[0].classList.add("hidden");
|
||||
holder.getElementsByClassName("confirm_holder_stage2")[0].classList.remove("hidden");
|
||||
const input = holder.getElementsByTagName("input")[0];
|
||||
if (input)
|
||||
{
|
||||
input.focus();
|
||||
}
|
||||
}
|
||||
|
||||
button_cancel.onclick = function(event)
|
||||
{
|
||||
const holder = event.target.parentElement.parentElement;
|
||||
holder.getElementsByClassName("confirm_holder_stage1")[0].classList.remove("hidden");
|
||||
holder.getElementsByClassName("confirm_holder_stage2")[0].classList.add("hidden");
|
||||
}
|
||||
delete button.dataset.onclick;
|
||||
}
|
||||
|
||||
common.init_all_button_with_confirm =
|
||||
function init_all_button_with_confirm()
|
||||
{
|
||||
const buttons = Array.from(document.getElementsByClassName("button_with_confirm"));
|
||||
for (const button of buttons)
|
||||
{
|
||||
setTimeout(() => common.init_button_with_confirm(button), 0);
|
||||
}
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.init_all_input_bind_to_button =
|
||||
function init_all_input_bind_to_button()
|
||||
{
|
||||
for (const input of document.querySelectorAll("*[data-bind-enter-to-button]"))
|
||||
{
|
||||
const button = document.getElementById(input.dataset.bindEnterToButton);
|
||||
if (button)
|
||||
{
|
||||
common.bind_box_to_button(input, button, false);
|
||||
delete input.dataset.bindEnterToButton;
|
||||
}
|
||||
}
|
||||
for (const input of document.querySelectorAll("*[data-bind-ctrl-enter-to-button]"))
|
||||
{
|
||||
const button = document.getElementById(input.dataset.bindCtrlEnterToButton);
|
||||
if (button)
|
||||
{
|
||||
common.bind_box_to_button(input, button, true);
|
||||
delete input.dataset.bindCtrlEnterToButton;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.init_enable_on_pageload =
|
||||
function init_enable_on_pageload(element)
|
||||
{
|
||||
/*
|
||||
To create an input element which is disabled at first, and is enabled when
|
||||
the DOM has completed loading, give it the disabled attribute and the
|
||||
class "enable_on_pageload".
|
||||
*/
|
||||
element.disabled = false;
|
||||
element.classList.remove("enable_on_pageload");
|
||||
}
|
||||
|
||||
common.init_all_enable_on_pageload =
|
||||
function init_all_enable_on_pageload()
|
||||
{
|
||||
const elements = Array.from(document.getElementsByClassName("enable_on_pageload"));
|
||||
for (const element of elements)
|
||||
{
|
||||
setTimeout(() => common.init_enable_on_pageload(element), 0);
|
||||
}
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.init_entry_with_history =
|
||||
function init_entry_with_history(input)
|
||||
{
|
||||
input.addEventListener("keydown", common.entry_with_history_hook);
|
||||
input.classList.remove("entry_with_history");
|
||||
}
|
||||
|
||||
common.init_all_entry_with_history =
|
||||
function init_all_entry_with_history()
|
||||
{
|
||||
const inputs = Array.from(document.getElementsByClassName("entry_with_history"));
|
||||
for (const input of inputs)
|
||||
{
|
||||
setTimeout(() => common.init_entry_with_history(input), 0);
|
||||
}
|
||||
}
|
||||
|
||||
common.entry_with_history_hook =
|
||||
function entry_with_history_hook(event)
|
||||
{
|
||||
const box = event.target;
|
||||
|
||||
if (box.entry_history === undefined)
|
||||
{box.entry_history = [];}
|
||||
|
||||
if (box.entry_history_pos === undefined)
|
||||
{box.entry_history_pos = null;}
|
||||
|
||||
if (event.key === "Enter")
|
||||
{
|
||||
if (box.value === "")
|
||||
{return;}
|
||||
box.entry_history.push(box.value);
|
||||
box.entry_history_pos = null;
|
||||
}
|
||||
else if (event.key === "Escape")
|
||||
{
|
||||
box.entry_history_pos = null;
|
||||
box.value = "";
|
||||
}
|
||||
|
||||
if (box.entry_history.length == 0)
|
||||
{return}
|
||||
|
||||
if (box.entry_history_pos !== null && box.value !== box.entry_history[box.entry_history_pos])
|
||||
{return;}
|
||||
|
||||
if (event.key === "ArrowUp")
|
||||
{
|
||||
if (box.entry_history_pos === null)
|
||||
{box.entry_history_pos = box.entry_history.length - 1;}
|
||||
else if (box.entry_history_pos == 0)
|
||||
{;}
|
||||
else
|
||||
{box.entry_history_pos -= 1;}
|
||||
|
||||
if (box.entry_history_pos === null)
|
||||
{box.value = "";}
|
||||
else
|
||||
{box.value = box.entry_history[box.entry_history_pos];}
|
||||
|
||||
setTimeout(function(){box.selectionStart = box.value.length;}, 0);
|
||||
}
|
||||
else if (event.key === "ArrowDown")
|
||||
{
|
||||
if (box.entry_history_pos === null)
|
||||
{;}
|
||||
else if (box.entry_history_pos == box.entry_history.length-1)
|
||||
{box.entry_history_pos = null;}
|
||||
else
|
||||
{box.entry_history_pos += 1;}
|
||||
|
||||
if (box.entry_history_pos === null)
|
||||
{box.value = "";}
|
||||
else
|
||||
{box.value = box.entry_history[box.entry_history_pos];}
|
||||
|
||||
setTimeout(function(){box.selectionStart = box.value.length;}, 0);
|
||||
}
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.init_tabbed_container =
|
||||
function init_tabbed_container(tabbed_container)
|
||||
{
|
||||
const button_container = document.createElement("div");
|
||||
button_container.className = "tab_buttons";
|
||||
tabbed_container.prepend(button_container);
|
||||
const tabs = Array.from(tabbed_container.getElementsByClassName("tab"));
|
||||
for (const tab of tabs)
|
||||
{
|
||||
tab.classList.add("hidden");
|
||||
const tab_id = tab.dataset.tabId || tab.dataset.tabTitle;
|
||||
tab.dataset.tabId = tab_id;
|
||||
tab.style.borderTopColor = "transparent";
|
||||
|
||||
const button = document.createElement("button");
|
||||
button.className = "tab_button tab_button_inactive";
|
||||
button.onclick = common.tabbed_container_switcher;
|
||||
button.innerText = tab.dataset.tabTitle;
|
||||
button.dataset.tabId = tab_id;
|
||||
button_container.append(button);
|
||||
}
|
||||
tabs[0].classList.remove("hidden");
|
||||
tabbed_container.dataset.activeTabId = tabs[0].dataset.tabId;
|
||||
button_container.firstElementChild.classList.remove("tab_button_inactive");
|
||||
button_container.firstElementChild.classList.add("tab_button_active");
|
||||
}
|
||||
|
||||
common.init_all_tabbed_container =
|
||||
function init_all_tabbed_container()
|
||||
{
|
||||
const tabbed_containers = Array.from(document.getElementsByClassName("tabbed_container"));
|
||||
for (const tabbed_container of tabbed_containers)
|
||||
{
|
||||
setTimeout(() => common.init_tabbed_container(tabbed_container), 0);
|
||||
}
|
||||
}
|
||||
|
||||
common.tabbed_container_switcher =
|
||||
function tabbed_container_switcher(event)
|
||||
{
|
||||
const tab_button = event.target;
|
||||
if (tab_button.classList.contains("tab_button_active"))
|
||||
{ return; }
|
||||
|
||||
const tab_id = tab_button.dataset.tabId;
|
||||
const tab_buttons = tab_button.parentElement.getElementsByClassName("tab_button");
|
||||
for (const tab_button of tab_buttons)
|
||||
{
|
||||
if (tab_button.dataset.tabId === tab_id)
|
||||
{
|
||||
tab_button.classList.remove("tab_button_inactive");
|
||||
tab_button.classList.add("tab_button_active");
|
||||
}
|
||||
else
|
||||
{
|
||||
tab_button.classList.remove("tab_button_active");
|
||||
tab_button.classList.add("tab_button_inactive");
|
||||
}
|
||||
}
|
||||
const tabbed_container = tab_button.closest(".tabbed_container");
|
||||
tabbed_container.dataset.activeTabId = tab_id;
|
||||
const tabs = tabbed_container.getElementsByClassName("tab");
|
||||
for (const tab of tabs)
|
||||
{
|
||||
if (tab.dataset.tabId === tab_id)
|
||||
{ tab.classList.remove("hidden"); }
|
||||
else
|
||||
{ tab.classList.add("hidden"); }
|
||||
}
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
common.on_pageload =
|
||||
function on_pageload()
|
||||
{
|
||||
common.init_all_atag_merge_params();
|
||||
common.init_all_button_with_confirm();
|
||||
common.init_all_enable_on_pageload();
|
||||
common.init_all_entry_with_history();
|
||||
common.init_all_input_bind_to_button();
|
||||
common.init_all_tabbed_container();
|
||||
}
|
||||
document.addEventListener("DOMContentLoaded", common.on_pageload);
|
||||
48
frontends/bringrss_flask/static/js/contextmenus.js
Normal file
48
frontends/bringrss_flask/static/js/contextmenus.js
Normal file
|
|
@ -0,0 +1,48 @@
|
|||
const contextmenus = {};
|
||||
|
||||
contextmenus.background_click =
|
||||
function background_click(event)
|
||||
{
|
||||
const contextmenu = event.target.closest(".contextmenu");
|
||||
if (! contextmenu)
|
||||
{
|
||||
contextmenus.hide_open_menus();
|
||||
return true;
|
||||
}
|
||||
}
|
||||
|
||||
contextmenus.hide_open_menus =
|
||||
function hide_open_menus()
|
||||
{
|
||||
const elements = document.getElementsByClassName("open_contextmenu");
|
||||
while (elements.length > 0)
|
||||
{
|
||||
elements[0].classList.remove("open_contextmenu");
|
||||
}
|
||||
}
|
||||
|
||||
contextmenus.menu_is_open =
|
||||
function menu_is_open()
|
||||
{
|
||||
return document.getElementsByClassName("open_contextmenu").length > 0;
|
||||
}
|
||||
|
||||
contextmenus.show_menu =
|
||||
function show_menu(event, menu)
|
||||
{
|
||||
contextmenus.hide_open_menus();
|
||||
menu.classList.add("open_contextmenu");
|
||||
const html = document.documentElement;
|
||||
const over_right = Math.max(0, event.clientX + menu.offsetWidth - html.clientWidth);
|
||||
const over_bottom = Math.max(0, event.clientY + menu.offsetHeight - html.clientHeight);
|
||||
const left = event.clientX - over_right;
|
||||
const top = event.clientY - over_bottom;
|
||||
menu.style.left = left + "px";
|
||||
menu.style.top = top + "px";
|
||||
}
|
||||
|
||||
function on_pageload()
|
||||
{
|
||||
document.body.addEventListener("click", contextmenus.background_click);
|
||||
}
|
||||
document.addEventListener("DOMContentLoaded", on_pageload);
|
||||
3
frontends/bringrss_flask/static/js/dompurify.js
Normal file
3
frontends/bringrss_flask/static/js/dompurify.js
Normal file
File diff suppressed because one or more lines are too long
110
frontends/bringrss_flask/static/js/hotkeys.js
Normal file
110
frontends/bringrss_flask/static/js/hotkeys.js
Normal file
|
|
@ -0,0 +1,110 @@
|
|||
const hotkeys = {};
|
||||
|
||||
hotkeys.HOTKEYS = {};
|
||||
hotkeys.HELPS = [];
|
||||
|
||||
hotkeys.hotkey_identifier =
|
||||
function hotkey_identifier(key, ctrlKey, shiftKey, altKey)
|
||||
{
|
||||
// Return the string that will represent this hotkey in the dictionary.
|
||||
return key.toLowerCase() + "." + (ctrlKey & 1) + "." + (shiftKey & 1) + "." + (altKey & 1);
|
||||
}
|
||||
|
||||
hotkeys.hotkey_human =
|
||||
function hotkey_human(key, ctrlKey, shiftKey, altKey)
|
||||
{
|
||||
// Return the string that will be displayed to the user to represent this hotkey.
|
||||
let mods = [];
|
||||
if (ctrlKey) { mods.push("CTRL"); }
|
||||
if (shiftKey) { mods.push("SHIFT"); }
|
||||
if (altKey) { mods.push("ALT"); }
|
||||
mods = mods.join("+");
|
||||
if (mods) { mods = mods + "+"; }
|
||||
return mods + key.toUpperCase();
|
||||
}
|
||||
|
||||
hotkeys.register_help =
|
||||
function register_help(help)
|
||||
{
|
||||
hotkeys.HELPS.push(help);
|
||||
}
|
||||
|
||||
hotkeys.register_hotkey =
|
||||
function register_hotkey(hotkey, action, description)
|
||||
{
|
||||
if (! Array.isArray(hotkey))
|
||||
{
|
||||
hotkey = hotkey.split(/\s+/g);
|
||||
}
|
||||
|
||||
const key = hotkey.pop();
|
||||
modifiers = hotkey.map(word => word.toLocaleLowerCase());
|
||||
const ctrlKey = modifiers.includes("control") || modifiers.includes("ctrl");
|
||||
const shiftKey = modifiers.includes("shift");
|
||||
const altKey = modifiers.includes("alt");
|
||||
|
||||
const identifier = hotkeys.hotkey_identifier(key, ctrlKey, shiftKey, altKey);
|
||||
const human = hotkeys.hotkey_human(key, ctrlKey, shiftKey, altKey);
|
||||
hotkeys.HOTKEYS[identifier] = {"action": action, "human": human, "description": description}
|
||||
}
|
||||
|
||||
hotkeys.should_prevent_hotkey =
|
||||
function should_prevent_hotkey(event)
|
||||
{
|
||||
/*
|
||||
If the user is currently in an input element, then the registered hotkey
|
||||
will be ignored and the browser will use its default behavior.
|
||||
*/
|
||||
if (event.target.tagName == "INPUT" && event.target.type == "checkbox")
|
||||
{
|
||||
return false;
|
||||
}
|
||||
else
|
||||
{
|
||||
return common.INPUT_TYPES.has(event.target.tagName);
|
||||
}
|
||||
}
|
||||
|
||||
hotkeys.show_all_hotkeys =
|
||||
function show_all_hotkeys()
|
||||
{
|
||||
// Display an Alert with a list of all the hotkeys.
|
||||
let lines = [];
|
||||
for (const identifier in hotkeys.HOTKEYS)
|
||||
{
|
||||
const line = hotkeys.HOTKEYS[identifier]["human"] + " : " + hotkeys.HOTKEYS[identifier]["description"];
|
||||
lines.push(line);
|
||||
}
|
||||
if (hotkeys.HELPS)
|
||||
{
|
||||
lines.push("");
|
||||
}
|
||||
for (const help of hotkeys.HELPS)
|
||||
{
|
||||
lines.push(help);
|
||||
}
|
||||
lines = lines.join("\n");
|
||||
alert(lines);
|
||||
}
|
||||
|
||||
hotkeys.hotkeys_listener =
|
||||
function hotkeys_listener(event)
|
||||
{
|
||||
// console.log(event.key);
|
||||
if (hotkeys.should_prevent_hotkey(event))
|
||||
{
|
||||
return;
|
||||
}
|
||||
|
||||
identifier = hotkeys.hotkey_identifier(event.key, event.ctrlKey, event.shiftKey, event.altKey);
|
||||
//console.log(identifier);
|
||||
if (identifier in hotkeys.HOTKEYS)
|
||||
{
|
||||
hotkeys.HOTKEYS[identifier]["action"](event);
|
||||
event.preventDefault();
|
||||
}
|
||||
}
|
||||
|
||||
window.addEventListener("keydown", hotkeys.hotkeys_listener);
|
||||
|
||||
hotkeys.register_hotkey("/", hotkeys.show_all_hotkeys, "Show hotkeys.");
|
||||
201
frontends/bringrss_flask/static/js/spinners.js
Normal file
201
frontends/bringrss_flask/static/js/spinners.js
Normal file
|
|
@ -0,0 +1,201 @@
|
|||
const spinners = {};
|
||||
|
||||
/*
|
||||
In general, spinners are used for functions that launch a callback, and the
|
||||
callback will close the spinner after it runs. But, if your initial function
|
||||
decides not to launch the callback (insufficient parameters, failed clientside
|
||||
checks, etc.), you can have it return spinners.BAIL and the spinners will close
|
||||
immediately. Of course, you're always welcome to use
|
||||
spinners.close_button_spinner(button), but this return value means you don't
|
||||
need to pull the button into a variable, as long as you weren't using the
|
||||
return value anyway.
|
||||
*/
|
||||
spinners.BAIL = "spinners.BAIL";
|
||||
|
||||
spinners.Spinner =
|
||||
function Spinner(element)
|
||||
{
|
||||
this.show = function(delay)
|
||||
{
|
||||
clearTimeout(this.delayed_showing_timeout);
|
||||
|
||||
if (delay)
|
||||
{
|
||||
this.delayed_showing_timeout = setTimeout(function(thisthis){thisthis.show()}, delay, this);
|
||||
}
|
||||
else
|
||||
{
|
||||
this.delayed_showing_timeout = null;
|
||||
this.element.classList.remove("hidden");
|
||||
}
|
||||
}
|
||||
|
||||
this.hide = function()
|
||||
{
|
||||
clearTimeout(this.delayed_showing_timeout);
|
||||
this.delayed_showing_timeout = null;
|
||||
|
||||
this.element.classList.add("hidden");
|
||||
}
|
||||
|
||||
this.delayed_showing_timeout = null;
|
||||
this.element = element;
|
||||
}
|
||||
|
||||
spinners.spinner_button_index = 0;
|
||||
spinners.button_spinner_groups = {};
|
||||
/*
|
||||
When a group member is closing, it will call the closer on all other members
|
||||
in the group. Of course, this would recurse forever without some kind of
|
||||
flagging, so this dict will hold group_id:true if a close is in progress,
|
||||
and be empty otherwise.
|
||||
*/
|
||||
spinners.spinner_group_closing = {};
|
||||
|
||||
spinners.add_to_spinner_group =
|
||||
function add_to_spinner_group(group_id, button)
|
||||
{
|
||||
if (!(group_id in spinners.button_spinner_groups))
|
||||
{
|
||||
spinners.button_spinner_groups[group_id] = [];
|
||||
}
|
||||
spinners.button_spinner_groups[group_id].push(button);
|
||||
}
|
||||
|
||||
spinners.close_button_spinner =
|
||||
function close_button_spinner(button)
|
||||
{
|
||||
window[button.dataset.spinnerCloser]();
|
||||
}
|
||||
|
||||
spinners.close_grouped_spinners =
|
||||
function close_grouped_spinners(group_id)
|
||||
{
|
||||
if (group_id && !(spinners.spinner_group_closing[group_id]))
|
||||
{
|
||||
spinners.spinner_group_closing[group_id] = true;
|
||||
for (const button of spinners.button_spinner_groups[group_id])
|
||||
{
|
||||
window[button.dataset.spinnerCloser]();
|
||||
}
|
||||
delete spinners.spinner_group_closing[group_id];
|
||||
}
|
||||
}
|
||||
|
||||
spinners.open_grouped_spinners =
|
||||
function open_grouped_spinners(group_id)
|
||||
{
|
||||
for (const button of spinners.button_spinner_groups[group_id])
|
||||
{
|
||||
window[button.dataset.spinnerOpener]();
|
||||
}
|
||||
}
|
||||
|
||||
spinners.init_button_with_spinner =
|
||||
function init_button_with_spinner()
|
||||
{
|
||||
/*
|
||||
To create a button that has a spinner, and cannot be clicked again while
|
||||
the action is running, assign it the class "button_with_spinner".
|
||||
When you're ready for the spinner to disappear, call
|
||||
spinners.close_button_spinner(button).
|
||||
|
||||
Optional:
|
||||
data-spinner-id: If you want to use your own element as the spinner,
|
||||
give its ID here. Otherwise a new one will be created.
|
||||
|
||||
data-spinner-delay: The number of milliseconds to wait before the
|
||||
spinner appears. For tasks that you expect to run very quickly,
|
||||
this helps prevent a pointlessly short spinner. Note that the button
|
||||
always becomes disabled immediately, and this delay only affects
|
||||
the separate spinner element.
|
||||
|
||||
data-holder-class: CSS class for the new span that holds the menu.
|
||||
|
||||
data-spinner-group: An opaque string. All button_with_spinner that have
|
||||
the same group will go into spinner mode when any of them is
|
||||
clicked. Useful if you want to have two copies of a button on the
|
||||
page, or two buttons which do opposite things and you only want one
|
||||
to run at a time.
|
||||
*/
|
||||
const buttons = Array.from(document.getElementsByClassName("button_with_spinner"));
|
||||
for (const button of buttons)
|
||||
{
|
||||
button.classList.remove("button_with_spinner");
|
||||
button.innerHTML = button.innerHTML.trim();
|
||||
|
||||
const holder = document.createElement("span");
|
||||
holder.classList.add("spinner_holder");
|
||||
holder.classList.add(button.dataset.holderClass || "spinner_holder");
|
||||
button.parentElement.insertBefore(holder, button);
|
||||
holder.appendChild(button);
|
||||
|
||||
if (button.dataset.spinnerGroup)
|
||||
{
|
||||
spinners.add_to_spinner_group(button.dataset.spinnerGroup, button);
|
||||
}
|
||||
|
||||
let spinner_element;
|
||||
if (button.dataset.spinnerId)
|
||||
{
|
||||
spinner_element = document.getElementById(button.dataset.spinnerId);
|
||||
spinner_element.classList.add("hidden");
|
||||
}
|
||||
else
|
||||
{
|
||||
spinner_element = document.createElement("span");
|
||||
spinner_element.innerText = button.dataset.spinnerText || "Working...";
|
||||
spinner_element.classList.add("hidden");
|
||||
holder.appendChild(spinner_element);
|
||||
}
|
||||
|
||||
const spin = new spinners.Spinner(spinner_element);
|
||||
const spin_delay = parseFloat(button.dataset.spinnerDelay) || 0;
|
||||
|
||||
button.dataset.spinnerOpener = "spinner_opener_" + spinners.spinner_button_index;
|
||||
window[button.dataset.spinnerOpener] = function spinner_opener()
|
||||
{
|
||||
spin.show(spin_delay);
|
||||
button.disabled = true;
|
||||
}
|
||||
// It is expected that the function referenced by onclick will call
|
||||
// spinners.close_button_spinner(button) when appropriate, since from
|
||||
// our perspective we cannot be sure when to close the spinner.
|
||||
button.dataset.spinnerCloser = "spinner_closer_" + spinners.spinner_button_index;
|
||||
window[button.dataset.spinnerCloser] = function spinner_closer()
|
||||
{
|
||||
spinners.close_grouped_spinners(button.dataset.spinnerGroup);
|
||||
spin.hide();
|
||||
button.disabled = false;
|
||||
}
|
||||
|
||||
const wrapped_onclick = button.onclick;
|
||||
button.removeAttribute('onclick');
|
||||
button.onclick = function(event)
|
||||
{
|
||||
if (button.dataset.spinnerGroup)
|
||||
{
|
||||
spinners.open_grouped_spinners(button.dataset.spinnerGroup);
|
||||
}
|
||||
else
|
||||
{
|
||||
window[button.dataset.spinnerOpener]();
|
||||
}
|
||||
const ret = wrapped_onclick(event);
|
||||
if (ret === spinners.BAIL)
|
||||
{
|
||||
window[button.dataset.spinnerCloser]();
|
||||
}
|
||||
return ret;
|
||||
}
|
||||
|
||||
spinners.spinner_button_index += 1;
|
||||
}
|
||||
}
|
||||
|
||||
spinners.on_pageload =
|
||||
function on_pageload()
|
||||
{
|
||||
spinners.init_button_with_spinner();
|
||||
}
|
||||
document.addEventListener("DOMContentLoaded", spinners.on_pageload);
|
||||
73
frontends/bringrss_flask/templates/about.html
Normal file
73
frontends/bringrss_flask/templates/about.html
Normal file
|
|
@ -0,0 +1,73 @@
|
|||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<title>About BringRSS</title>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
|
||||
<link rel="icon" href="/favicon.png" type="image/png"/>
|
||||
<link rel="stylesheet" href="/static/css/common.css"/>
|
||||
<link rel="stylesheet" href="/static/css/bringrss.css"/>
|
||||
{% if theme %}<link rel="stylesheet" href="/static/css/theme_{{theme}}.css">{% endif %}
|
||||
<script src="/static/js/common.js"></script>
|
||||
|
||||
<style>
|
||||
#content_body
|
||||
{
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
justify-content: center;
|
||||
align-items: center;
|
||||
}
|
||||
#content_body > .link_group,
|
||||
#content_body > .nice_link
|
||||
{
|
||||
width: 90%;
|
||||
max-width: 600px;
|
||||
}
|
||||
.link_group
|
||||
{
|
||||
display: grid;
|
||||
grid-auto-flow: column;
|
||||
grid-auto-columns: 1fr;
|
||||
grid-gap: 8px;
|
||||
}
|
||||
.nice_link
|
||||
{
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
justify-content: center;
|
||||
align-items: center;
|
||||
margin: 8px 0;
|
||||
height: 40px;
|
||||
background-color: var(--color_transparency);
|
||||
}
|
||||
.nice_link:hover
|
||||
{
|
||||
background-color: var(--color_secondary);
|
||||
}
|
||||
</style>
|
||||
</head>
|
||||
|
||||
|
||||
<body>
|
||||
<div id="content_body">
|
||||
<a class="nice_link" href="/">Home</a>
|
||||
<div class="link_group">
|
||||
<a class="nice_link" href="https://github.com/voussoir/bringrss">GitHub</a>
|
||||
<a class="nice_link" href="https://gitlab.com/voussoir/bringrss">GitLab</a>
|
||||
<a class="nice_link" href="https://codeberg.org/voussoir/bringrss">Codeberg</a>
|
||||
</div>
|
||||
<div class="link_group">
|
||||
<a class="nice_link" href="?theme=turquoise">Turquoise</a>
|
||||
<a class="nice_link" href="?theme=pearl">Pearl</a>
|
||||
<a class="nice_link" href="?theme=slate">Slate</a>
|
||||
<a class="nice_link" href="?theme=onyx">Onyx</a>
|
||||
</div>
|
||||
<a class="nice_link donate" href="https://voussoir.net/donate">voussoir.net/donate</a>
|
||||
</div>
|
||||
</body>
|
||||
|
||||
|
||||
<script type="text/javascript">
|
||||
</script>
|
||||
</html>
|
||||
738
frontends/bringrss_flask/templates/feed_settings.html
Normal file
738
frontends/bringrss_flask/templates/feed_settings.html
Normal file
|
|
@ -0,0 +1,738 @@
|
|||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
{% import "header.html" as header %}
|
||||
<title>{{feed.display_name}}</title>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
|
||||
<link rel="icon" href="/favicon.png" type="image/png"/>
|
||||
<link rel="stylesheet" href="/static/css/common.css">
|
||||
<link rel="stylesheet" href="/static/css/bringrss.css">
|
||||
{% if theme %}<link rel="stylesheet" href="/static/css/theme_{{theme}}.css">{% endif %}
|
||||
<script src="/static/js/common.js"></script>
|
||||
<script src="/static/js/api.js"></script>
|
||||
<script src="/static/js/spinners.js"></script>
|
||||
|
||||
<style>
|
||||
p, pre
|
||||
{
|
||||
margin-top: 0;
|
||||
margin-bottom: 0;
|
||||
}
|
||||
h1:first-child
|
||||
{
|
||||
margin-top: 0;
|
||||
}
|
||||
|
||||
#feed,
|
||||
.group
|
||||
{
|
||||
display: grid;
|
||||
grid-auto-flow: row;
|
||||
grid-gap: 8px;
|
||||
}
|
||||
|
||||
#set_title_input,
|
||||
#set_rss_url_input,
|
||||
#set_web_url_input
|
||||
{
|
||||
width: 100%;
|
||||
max-width: 400px;
|
||||
}
|
||||
|
||||
#set_http_headers_input
|
||||
{
|
||||
width: 100%;
|
||||
max-width: 400px;
|
||||
height: 150px;
|
||||
}
|
||||
|
||||
#set_autorefresh_interval_inputs input
|
||||
{
|
||||
width: 3em;
|
||||
text-align: right;
|
||||
}
|
||||
.group
|
||||
{
|
||||
border: 1px solid var(--color_highlight);
|
||||
border-radius: 4px;
|
||||
padding: 4px;
|
||||
}
|
||||
#filters_group h2:first-child,
|
||||
.group h2:first-child
|
||||
{
|
||||
margin-top: 0;
|
||||
}
|
||||
|
||||
#filters .filter
|
||||
{
|
||||
margin: 8px;
|
||||
padding: 8px;
|
||||
max-width: 500px;
|
||||
background-color: var(--color_transparency);
|
||||
display: grid;
|
||||
grid-auto-columns: 1fr auto auto;
|
||||
grid-column-gap: 8px;
|
||||
grid-auto-flow: column;
|
||||
}
|
||||
#filters .filter .name,
|
||||
#filters .filter .edit_link
|
||||
{
|
||||
align-self: center;
|
||||
}
|
||||
#filters #add_filter_select
|
||||
{
|
||||
width: 200px;
|
||||
}
|
||||
#filter_rearrange_guideline
|
||||
{
|
||||
display: none;
|
||||
position: fixed;
|
||||
border: 1px solid var(--color_text_normal);
|
||||
z-index: -1;
|
||||
}
|
||||
</style>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
{{header.make_header(site=site, request=request)}}
|
||||
<div id="content_body">
|
||||
<div id="feed" class="panel" data-id="{{feed.id}}">
|
||||
<h1 id="feed_title_header">{{feed.display_name}}</h1>
|
||||
<p>ID: <code>{{feed.id}}</code></p>
|
||||
|
||||
{% if feed.description %}
|
||||
<p>{{feed.description}}</p>
|
||||
{% endif %}
|
||||
|
||||
<div>
|
||||
<input type="text" id="set_title_input" placeholder="Title" value="{{feed.title or ''}}" data-bind-enter-to-button="set_title_button"/>
|
||||
<button id="set_title_button" class="button_with_spinner" data-spinner-text="⌛" onclick="return set_title_form(event);">Set title</button>
|
||||
</div>
|
||||
<div>
|
||||
<input type="text" id="set_rss_url_input" placeholder="RSS URL" value="{{feed.rss_url or ''}}" data-bind-enter-to-button="set_rss_url_button"/>
|
||||
<button id="set_rss_url_button" class="button_with_spinner" data-spinner-text="⌛" onclick="return set_rss_url_form(event);">Set RSS URL</button>
|
||||
</div>
|
||||
<div>
|
||||
<input type="text" id="set_web_url_input" placeholder="Web URL" value="{{feed.web_url or ''}}" data-bind-enter-to-button="set_web_url_button"/>
|
||||
<button id="set_web_url_button" class="button_with_spinner" data-spinner-text="⌛" onclick="return set_web_url_form(event);">Set Web URL</button>
|
||||
</div>
|
||||
|
||||
<div>
|
||||
<img id="icon_img" src="/feed/{{feed.id}}/icon.png"/>
|
||||
<input id="set_icon_input" type="file"/>
|
||||
<button id="set_icon_button" class="button_with_spinner" data-spinner-text="⌛" onclick="return set_icon_form(event)">Set icon</button>
|
||||
</div>
|
||||
|
||||
{% set autorefresh_group_hidden = '' if feed.rss_url else 'hidden' %}
|
||||
<div id="autorefresh_group" class="group {{autorefresh_group_hidden}}">
|
||||
{% set checked = 'checked' if feed.autorefresh_interval > 0 else '' %}
|
||||
<span>
|
||||
<label><input type="checkbox" {{checked}} onchange="return set_autorefresh_enabled_form(event);"/> Automatically refresh this feed regularly.</label>
|
||||
<span id="set_autorefresh_enabled_spinner" class="hidden">⌛</span>
|
||||
</span>
|
||||
|
||||
{% set autorefresh_interval_hidden = '' if checked else 'hidden' %}
|
||||
<p id="set_autorefresh_interval_inputs" class="{{autorefresh_interval_hidden}}">
|
||||
{% set interval = feed.autorefresh_interval|abs %}
|
||||
{% set hours = (interval / 3600)|int %}
|
||||
{% set minutes = ((interval % 3600) / 60)|int %}
|
||||
Refresh every
|
||||
<input type="number" min="0" id="autorefresh_input_hours" size="4" value="{{hours}}"/> hours,
|
||||
<input type="number" min="0" id="autorefresh_input_minutes" size="4" value="{{minutes}}"/> minutes
|
||||
<button class="button_with_spinner" data-spinner-text="⌛" onclick="return set_autorefresh_interval_form(event);">Set autorefresh</button>
|
||||
</p>
|
||||
<p>Note: autorefresh is not inherited from parent to child. When you manually click the refresh button on a parent, its children will also be refreshed, but if the parent is refreshed automatically, the children will wait for their own autorefresh.</p>
|
||||
|
||||
{% if feed.last_refresh %}
|
||||
<p>Last refresh: {{feed.last_refresh|timestamp_to_8601_local}}</p>
|
||||
{% endif %}
|
||||
|
||||
{% if feed.next_refresh < INF %}
|
||||
<p>Next refresh: {{feed.next_refresh|timestamp_to_8601_local}}</p>
|
||||
{% endif %}
|
||||
|
||||
{% if feed.last_refresh_error %}
|
||||
<p>The last refresh attempt at {{feed.last_refresh_attempt|timestamp_to_8601_local}} encountered the following error:</p>
|
||||
<pre>
|
||||
{{-feed.last_refresh_error|trim-}}
|
||||
</pre>
|
||||
{% endif %}
|
||||
</div>
|
||||
|
||||
<div class="group">
|
||||
{% set checked = 'checked' if feed.refresh_with_others else '' %}
|
||||
<span>
|
||||
<label><input type="checkbox" {{checked}} onchange="return set_refresh_with_others_form(event);"/> Refresh this feed and its children when I refresh its parent or press the "Refresh all" button.</label>
|
||||
<span id="set_refresh_with_others_spinner" class="hidden">⌛</span>
|
||||
</span>
|
||||
<p>If disabled, this feed will only be refreshed when you click its own refresh button, or when its autorefresh timer is ready.</p>
|
||||
</div>
|
||||
|
||||
<div id="isolate_guids_group" class="group">
|
||||
{% set checked = 'checked' if feed.isolate_guids else '' %}
|
||||
<span>
|
||||
<label><input type="checkbox" {{checked}} onchange="return set_isolate_guids_form(event);"/> Isolate RSS GUIDs from other feeds.</label>
|
||||
<span id="set_isolate_guids_spinner" class="hidden">⌛</span>
|
||||
</span>
|
||||
<p>When feeds are refreshed, the system uses GUIDs and other news attributes to detect which items are new and which are duplicates from the previous refresh.</p>
|
||||
<p>If the feed is isolated, the GUIDs will only be used to search for duplicates within this feed. If the feed is not isolated, the GUIDs will be used to search for duplicates among all news in the database.</p>
|
||||
<p>If you have two feeds that may produce the same items (e.g. two newspaper category feeds, and a news article belongs to both categories), this setting will control whether the news item appears in both feeds or just the one that got it first.</p>
|
||||
</div>
|
||||
|
||||
<div id="filters_group" class="group">
|
||||
<h2>Filters</h2>
|
||||
<p>Filters will execute in the order they are listed here:</p>
|
||||
<div id="filter_rearrange_guideline"></div>
|
||||
<div
|
||||
id="filters"
|
||||
ondragstart="return filter_drag_start(event);"
|
||||
ondragend="return filter_drag_end(event);"
|
||||
ondragover="return filter_drag_over(event);"
|
||||
ondragenter="return filter_drag_enter(event);"
|
||||
ondragleave="return filter_drag_leave(event);"
|
||||
ondrop="return filter_drag_drop(event);"
|
||||
>
|
||||
{% for filt in feed_filters %}
|
||||
<div class="filter" data-id="{{filt.id}}" draggable="true">
|
||||
<span class="name">{{filt.display_name}}</span>
|
||||
<a class="edit_link" href="/filter/{{filt.id}}">Edit</a>
|
||||
<button
|
||||
class="red_button button_with_confirm"
|
||||
data-prompt="Remove this filter?"
|
||||
data-onclick="return remove_filter_form(event);"
|
||||
>Remove</button>
|
||||
</div>
|
||||
{% endfor %}
|
||||
</div>
|
||||
<select id="add_filter_select" onchange="return add_filter_form(event);">
|
||||
<option value="">Add another filter</option>
|
||||
{% for filt in available_filters %}
|
||||
<option value="{{filt.id}}">{{filt.display_name}}</option>
|
||||
{% endfor %}
|
||||
</select>
|
||||
<span id="set_filters_spinner" class="hidden">⌛</span>
|
||||
</div>
|
||||
|
||||
{% set http_headers_hidden = '' if feed.rss_url else 'hidden' %}
|
||||
<div id="http_headers_group" class="group {{http_headers_hidden}}">
|
||||
<p>If you need to define additional HTTP headers which will be sent on every refresh request for this feed, you can add them below. Write one header per line like <code>Key: value</code>, e.g. <code>Host: example.com</code></p>
|
||||
<textarea id="set_http_headers_input" placeholder="HTTP headers" data-bind-ctrl-enter-to-button="set_http_headers_button">{{feed.http_headers|http_headers_dict_to_lines}}</textarea>
|
||||
<button id="set_http_headers_button" class="button_with_spinner" data-spinner-text="⌛" onclick="return set_http_headers_form(event);">Set HTTP headers</button>
|
||||
</div>
|
||||
|
||||
<div>
|
||||
<button
|
||||
class="red_button button_with_confirm"
|
||||
data-prompt="Delete feed and all associated news?"
|
||||
data-onclick="return delete_feed_form(event);"
|
||||
>Delete feed</button>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</body>
|
||||
|
||||
<script type="text/javascript">
|
||||
const FEED_ID = {{feed.id}};
|
||||
const set_autorefresh_enabled_spinner = new spinners.Spinner(document.getElementById("set_autorefresh_enabled_spinner"));
|
||||
const set_refresh_with_others_spinner = new spinners.Spinner(document.getElementById("set_refresh_with_others_spinner"));
|
||||
const set_isolate_guids_spinner = new spinners.Spinner(document.getElementById("set_isolate_guids_spinner"));
|
||||
|
||||
const filter_rearrange_guideline = document.getElementById("filter_rearrange_guideline");
|
||||
|
||||
function read_autorefresh_inputs()
|
||||
{
|
||||
const hours = parseInt(document.getElementById("autorefresh_input_hours").value);
|
||||
const minutes = parseInt(document.getElementById("autorefresh_input_minutes").value);
|
||||
return (hours * 3600) + (minutes * 60);
|
||||
}
|
||||
|
||||
function write_autorefresh_inputs(interval)
|
||||
{
|
||||
document.getElementById("autorefresh_input_hours").value = Math.floor(interval / 3600);
|
||||
document.getElementById("autorefresh_input_minutes").value = Math.ceil((interval % 3600) / 60);
|
||||
}
|
||||
|
||||
function set_autorefresh_enabled_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
set_autorefresh_enabled_spinner.hide();
|
||||
if (response.meta.status != 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
const interval = response.data.autorefresh_interval;
|
||||
if (interval > 0)
|
||||
{
|
||||
inputs.classList.remove("hidden");
|
||||
write_autorefresh_inputs(interval);
|
||||
}
|
||||
else
|
||||
{
|
||||
inputs.classList.add("hidden");
|
||||
}
|
||||
}
|
||||
const inputs = document.getElementById("set_autorefresh_interval_inputs");
|
||||
if (event.target.checked)
|
||||
{
|
||||
inputs.classList.remove("hidden");
|
||||
if (read_autorefresh_inputs() === 0)
|
||||
{
|
||||
write_autorefresh_inputs(86400);
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
const value = -1 * read_autorefresh_inputs();
|
||||
set_autorefresh_enabled_spinner.show();
|
||||
api.feeds.set_autorefresh_interval(FEED_ID, value, callback);
|
||||
}
|
||||
}
|
||||
|
||||
function set_autorefresh_interval_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
spinners.close_button_spinner(button);
|
||||
if (response.meta.status != 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
}
|
||||
const button = event.target;
|
||||
const value = read_autorefresh_inputs();
|
||||
api.feeds.set_autorefresh_interval(FEED_ID, value, callback);
|
||||
}
|
||||
|
||||
function set_http_headers_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
spinners.close_button_spinner(button);
|
||||
if (response.meta.status != 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
if (input.value !== http_headers)
|
||||
{
|
||||
// Don't overwrite the text if they have already started changing it.
|
||||
return;
|
||||
}
|
||||
const lines = [];
|
||||
for (const [key, value] of Object.entries(response.data.http_headers))
|
||||
{
|
||||
lines.push(`${key}: ${value}`);
|
||||
}
|
||||
input.value = lines.join("\n");
|
||||
}
|
||||
const button = document.getElementById("set_http_headers_button");
|
||||
const input = document.getElementById("set_http_headers_input");
|
||||
const http_headers = input.value;
|
||||
api.feeds.set_http_headers(FEED_ID, http_headers, callback);
|
||||
}
|
||||
|
||||
function set_icon_form(event)
|
||||
{
|
||||
const button = document.getElementById("set_icon_button");
|
||||
const input = document.getElementById("set_icon_input");
|
||||
if (input.files.length == 0)
|
||||
{
|
||||
return spinners.BAIL;
|
||||
}
|
||||
const file = input.files[0];
|
||||
const reader = new FileReader();
|
||||
function callback(response)
|
||||
{
|
||||
spinners.close_button_spinner(button);
|
||||
if (response.meta.status != 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
const icon_url = `/feed/${FEED_ID}/icon.png`
|
||||
const img = document.getElementById("icon_img");
|
||||
promise = fetch(icon_url, {cache: "reload"});
|
||||
promise.then(() => {img.src = icon_url});
|
||||
}
|
||||
reader.onload = function(event)
|
||||
{
|
||||
const image_base64 = reader.result;
|
||||
api.feeds.set_icon(FEED_ID, image_base64, callback);
|
||||
}
|
||||
reader.readAsDataURL(file);
|
||||
}
|
||||
|
||||
function set_isolate_guids_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
set_isolate_guids_spinner.hide();
|
||||
if (response.meta.status != 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
}
|
||||
set_isolate_guids_spinner.show();
|
||||
const isolate_guids = Number(event.target.checked)
|
||||
api.feeds.set_isolate_guids(FEED_ID, isolate_guids, callback);
|
||||
}
|
||||
|
||||
function set_refresh_with_others_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
set_refresh_with_others_spinner.hide();
|
||||
if (response.meta.status != 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
}
|
||||
set_refresh_with_others_spinner.show();
|
||||
api.feeds.set_refresh_with_others(FEED_ID, event.target.checked, callback);
|
||||
}
|
||||
|
||||
function set_rss_url_form(event)
|
||||
{
|
||||
const button = event.target;
|
||||
function callback(response)
|
||||
{
|
||||
spinners.close_button_spinner(button);
|
||||
if (response.meta.status != 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
input.value = response.data.rss_url;
|
||||
if (response.data.rss_url === null)
|
||||
{
|
||||
document.getElementById("autorefresh_group").classList.add("hidden");
|
||||
document.getElementById("http_headers_group").classList.add("hidden");
|
||||
document.getElementById("isolate_guids_group").classList.add("hidden");
|
||||
}
|
||||
else
|
||||
{
|
||||
document.getElementById("autorefresh_group").classList.remove("hidden");
|
||||
document.getElementById("http_headers_group").classList.remove("hidden");
|
||||
document.getElementById("isolate_guids_group").classList.remove("hidden");
|
||||
}
|
||||
}
|
||||
const input = document.getElementById("set_rss_url_input");
|
||||
const rss_url = input.value.trim();
|
||||
api.feeds.set_rss_url(FEED_ID, rss_url, callback);
|
||||
}
|
||||
|
||||
function set_title_form(event)
|
||||
{
|
||||
const button = event.target;
|
||||
function callback(response)
|
||||
{
|
||||
spinners.close_button_spinner(button);
|
||||
if (response.meta.status != 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
const header = document.getElementById("feed_title_header");
|
||||
header.innerText = response.data.display_name;
|
||||
document.title = response.data.display_name;
|
||||
input.value = response.data.title;
|
||||
}
|
||||
const input = document.getElementById("set_title_input");
|
||||
const title = input.value.trim();
|
||||
api.feeds.set_title(FEED_ID, title, callback);
|
||||
}
|
||||
|
||||
function set_web_url_form(event)
|
||||
{
|
||||
const button = event.target;
|
||||
function callback(response)
|
||||
{
|
||||
spinners.close_button_spinner(button);
|
||||
if (response.meta.status != 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
input.value = response.data.web_url;
|
||||
}
|
||||
const input = document.getElementById("set_web_url_input");
|
||||
const web_url = input.value.trim();
|
||||
api.feeds.set_web_url(FEED_ID, web_url, callback);
|
||||
}
|
||||
|
||||
function add_filter_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
set_filters_spinner.classList.add("hidden");
|
||||
select.disabled = false;
|
||||
if (response.meta.status !== 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
const add_filter_select = document.getElementById("add_filter_select");
|
||||
let selected_name;
|
||||
const options = add_filter_select.getElementsByTagName("option");
|
||||
for (const option of options)
|
||||
{
|
||||
if (option.value === selected_id)
|
||||
{
|
||||
option.parentElement.removeChild(option);
|
||||
selected_name = option.innerText;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
const filter_div = document.createElement("div");
|
||||
filter_div.classList.add("filter");
|
||||
filter_div.dataset.id = selected_id;
|
||||
filter_div.draggable = true;
|
||||
|
||||
const name = document.createElement("span");
|
||||
name.classList.add("name");
|
||||
name.innerText = selected_name;
|
||||
filter_div.appendChild(name);
|
||||
|
||||
const edit_link = document.createElement("a");
|
||||
edit_link.href = `/filter/${selected_id}`;
|
||||
edit_link.classList.add("edit_link");
|
||||
edit_link.innerText = "Edit";
|
||||
filter_div.appendChild(edit_link);
|
||||
|
||||
const remove_button = document.createElement("button");
|
||||
remove_button.classList.add("red_button");
|
||||
remove_button.classList.add("button_with_confirm");
|
||||
remove_button.innerText = "Remove";
|
||||
remove_button.dataset.prompt = "Remove this filter?"
|
||||
remove_button.dataset.onclick = "return remove_filter_form(event);";
|
||||
filter_div.appendChild(remove_button);
|
||||
common.init_button_with_confirm(remove_button);
|
||||
|
||||
filter_list.appendChild(filter_div);
|
||||
}
|
||||
if (event.target.value === "")
|
||||
{
|
||||
return;
|
||||
}
|
||||
const select = event.target;
|
||||
const filter_list = document.getElementById("filters");
|
||||
const selected_id = select.value;
|
||||
const filter_ids = [];
|
||||
for (const filter of filter_list.querySelectorAll(".filter"))
|
||||
{
|
||||
filter_ids.push(filter.dataset.id);
|
||||
}
|
||||
filter_ids.push(selected_id);
|
||||
api.feeds.set_filters(FEED_ID, filter_ids, callback);
|
||||
|
||||
const set_filters_spinner = document.getElementById("set_filters_spinner");
|
||||
set_filters_spinner.classList.remove("hidden");
|
||||
select.disabled = true;
|
||||
}
|
||||
|
||||
function remove_filter_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
if (response.meta.status !== 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
const new_option = document.createElement("option");
|
||||
new_option.value = deleting_filter.dataset.id;
|
||||
new_option.innerText = deleting_filter.querySelector(".name").innerText;
|
||||
document.getElementById("add_filter_select").appendChild(new_option);
|
||||
|
||||
filter_list.removeChild(deleting_filter);
|
||||
}
|
||||
|
||||
const button = event.target;
|
||||
const deleting_filter = button.closest(".filter");
|
||||
|
||||
const filter_list = document.getElementById("filters");
|
||||
const filter_ids = [];
|
||||
for (const filter of filter_list.querySelectorAll(".filter"))
|
||||
{
|
||||
if (filter === deleting_filter)
|
||||
{
|
||||
continue;
|
||||
}
|
||||
filter_ids.push(filter.dataset.id);
|
||||
}
|
||||
api.feeds.set_filters(FEED_ID, filter_ids, callback);
|
||||
}
|
||||
|
||||
let dragging_filter = null;
|
||||
function filter_drag_start(event)
|
||||
{
|
||||
const filter = event.target.closest(".filter");
|
||||
if (! filter)
|
||||
{
|
||||
return false;
|
||||
}
|
||||
dragging_filter = filter;
|
||||
}
|
||||
function filter_drag_end(event)
|
||||
{
|
||||
dragging_filter = null;
|
||||
filter_rearrange_guideline.style.display = "";
|
||||
}
|
||||
function filter_drag_above_below(event, target)
|
||||
{
|
||||
const target_rect = target.getBoundingClientRect();
|
||||
const cursor_y_percentage = (event.clientY - target_rect.y) / target.offsetHeight;
|
||||
if (cursor_y_percentage < 0.5)
|
||||
{
|
||||
return "above";
|
||||
}
|
||||
else
|
||||
{
|
||||
return "below";
|
||||
}
|
||||
}
|
||||
function filter_drag_over(event)
|
||||
{
|
||||
const target = event.target.closest(".filter");
|
||||
if (! target)
|
||||
{
|
||||
return false;
|
||||
}
|
||||
if (target === dragging_filter)
|
||||
{
|
||||
filter_rearrange_guideline.style.display = "";
|
||||
return false;
|
||||
}
|
||||
|
||||
event.preventDefault();
|
||||
|
||||
filter_rearrange_guideline.style.display = "block";
|
||||
|
||||
const target_rect = target.getBoundingClientRect();
|
||||
const cursor_y_percentage = (event.clientY - target_rect.y) / target.offsetHeight;
|
||||
const drag_position = filter_drag_above_below(event, target);
|
||||
if (drag_position == "above")
|
||||
{
|
||||
filter_rearrange_guideline.style.width = target_rect.width + "px";
|
||||
filter_rearrange_guideline.style.height = "0px";
|
||||
filter_rearrange_guideline.style.left = target_rect.x + "px";
|
||||
filter_rearrange_guideline.style.top = (target_rect.y - 4) + "px";
|
||||
}
|
||||
else
|
||||
{
|
||||
filter_rearrange_guideline.style.width = target_rect.width + "px";
|
||||
filter_rearrange_guideline.style.height = "0px";
|
||||
filter_rearrange_guideline.style.left = target_rect.x + "px";
|
||||
filter_rearrange_guideline.style.top = (target_rect.y + target_rect.height + 4) + "px";
|
||||
}
|
||||
}
|
||||
function filter_drag_enter(event)
|
||||
{
|
||||
}
|
||||
function filter_drag_leave(event)
|
||||
{
|
||||
}
|
||||
function filter_drag_drop(event)
|
||||
{
|
||||
const dragged_filter = dragging_filter;
|
||||
dragging_filter = null;
|
||||
|
||||
const filters = document.getElementById("filters");
|
||||
|
||||
if (event.target.closest(".filter"))
|
||||
{
|
||||
const target = event.target.closest(".filter");
|
||||
if (target === dragged_filter)
|
||||
{
|
||||
return false;
|
||||
}
|
||||
event.preventDefault();
|
||||
const target_rect = target.getBoundingClientRect();
|
||||
const cursor_y_percentage = (event.clientY - target_rect.y) / target.offsetHeight;
|
||||
const drag_position = filter_drag_above_below(event, target);
|
||||
if (drag_position === "above")
|
||||
{
|
||||
filters.insertBefore(dragged_filter, target);
|
||||
}
|
||||
else
|
||||
{
|
||||
filters.removeChild(dragged_filter);
|
||||
target.parentElement.insertBefore(dragged_filter, target.nextElementSibling);
|
||||
}
|
||||
}
|
||||
else if (event.target.closest("#filters"))
|
||||
{
|
||||
let above_this = null;
|
||||
for (const filter of filters.children)
|
||||
{
|
||||
if (filter === dragged_filter)
|
||||
{
|
||||
continue;
|
||||
}
|
||||
filter_rect = filter.getBoundingClientRect();
|
||||
if (event.clientY < filter_rect.y)
|
||||
{
|
||||
above_this = filter;
|
||||
break;
|
||||
}
|
||||
}
|
||||
if (above_this)
|
||||
{
|
||||
filters.removeChild(dragged_filter);
|
||||
above_this.parentElement.insertBefore(dragged_filter, above_this);
|
||||
}
|
||||
else
|
||||
{
|
||||
filters.removeChild(dragged_filter);
|
||||
filters.appendChild(dragged_filter);
|
||||
}
|
||||
}
|
||||
|
||||
const set_filters_spinner = document.getElementById("set_filters_spinner");
|
||||
|
||||
function callback(response)
|
||||
{
|
||||
set_filters_spinner.classList.add("hidden");
|
||||
if (response.meta.status != 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
}
|
||||
filter_rearrange_guideline.style.display = "";
|
||||
const filter_ids = [];
|
||||
for (const filter of filters.children)
|
||||
{
|
||||
filter_ids.push(filter.dataset.id);
|
||||
}
|
||||
api.feeds.set_filters(FEED_ID, filter_ids, callback);
|
||||
set_filters_spinner.classList.remove("hidden");
|
||||
}
|
||||
|
||||
function delete_feed_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
if (response.meta.status !== 200 || ! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
window.location.href = "/";
|
||||
}
|
||||
api.feeds.delete(FEED_ID, callback);
|
||||
}
|
||||
|
||||
function on_pageload()
|
||||
{
|
||||
}
|
||||
document.addEventListener("DOMContentLoaded", on_pageload);
|
||||
</script>
|
||||
</html>
|
||||
388
frontends/bringrss_flask/templates/filters.html
Normal file
388
frontends/bringrss_flask/templates/filters.html
Normal file
|
|
@ -0,0 +1,388 @@
|
|||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
{% import "header.html" as header %}
|
||||
<title>Filters</title>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
|
||||
<link rel="icon" href="/favicon.png" type="image/png"/>
|
||||
<link rel="stylesheet" href="/static/css/common.css">
|
||||
<link rel="stylesheet" href="/static/css/bringrss.css"/>
|
||||
{% if theme %}<link rel="stylesheet" href="/static/css/theme_{{theme}}.css">{% endif %}
|
||||
<script src="/static/js/common.js"></script>
|
||||
<script src="/static/js/api.js"></script>
|
||||
<script src="/static/js/spinners.js"></script>
|
||||
|
||||
<style>
|
||||
h2:first-child
|
||||
{
|
||||
margin-top: 0;
|
||||
}
|
||||
|
||||
@media screen and (min-width: 800px)
|
||||
{
|
||||
#content_body
|
||||
{
|
||||
display: grid;
|
||||
grid-template:
|
||||
"left right"
|
||||
/1fr 450px;
|
||||
min-height: 0;
|
||||
}
|
||||
}
|
||||
@media screen and (max-width: 800px)
|
||||
{
|
||||
#content_body
|
||||
{
|
||||
display: grid;
|
||||
grid-template:
|
||||
"left" auto
|
||||
"right" auto
|
||||
/1fr;
|
||||
}
|
||||
}
|
||||
|
||||
#left,
|
||||
#right
|
||||
{
|
||||
min-height: 0;
|
||||
overflow-y: auto;
|
||||
}
|
||||
#left
|
||||
{
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
gap: 8px;
|
||||
}
|
||||
.filter textarea
|
||||
{
|
||||
min-width: 300px;
|
||||
width: 45%;
|
||||
height: 75px;
|
||||
}
|
||||
.filter .error_message
|
||||
{
|
||||
color: red;
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
#right
|
||||
{
|
||||
min-height: 0;
|
||||
overflow-y: auto;
|
||||
}
|
||||
#right pre
|
||||
{
|
||||
width: 100%;
|
||||
border: 1px solid var(--color_text_normal);
|
||||
border-radius: 4px;
|
||||
padding: 4px;
|
||||
overflow-x: auto;
|
||||
}
|
||||
</style>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
{{header.make_header(site=site, request=request)}}
|
||||
<div id="content_body">
|
||||
<div id="left">
|
||||
{% for filt in filters %}
|
||||
<div id="filter_{{filt.id}}" data-id="{{filt.id}}" class="filter panel">
|
||||
<h2 class="name_header">{{filt.display_name}}</h2>
|
||||
<input type="text" class="set_name_input" placeholder="Name" value="{{filt.name or ''}}" data-bind-enter-to-button="{{filt.id}}_update_button" spellcheck="false"/>
|
||||
|
||||
<br/>
|
||||
|
||||
<textarea class="set_conditions_input" data-bind-ctrl-enter-to-button="{{filt.id}}_update_button" placeholder="Conditions" spellcheck="false">{{filt._conditions}}</textarea>
|
||||
|
||||
<textarea class="set_actions_input" data-bind-ctrl-enter-to-button="{{filt.id}}_update_button" placeholder="Actions" spellcheck="false">{{filt._actions}}</textarea>
|
||||
|
||||
<br/>
|
||||
|
||||
<button id="{{filt.id}}_update_button" class="set_actions_button button_with_spinner" data-spinner-text="⌛" onclick="return update_filter_form(event);">Update</button>
|
||||
|
||||
<br/>
|
||||
|
||||
<button
|
||||
class="red_button button_with_confirm"
|
||||
data-prompt="Delete filter?"
|
||||
data-onclick="return delete_filter_form(event);"
|
||||
>Delete filter</button>
|
||||
|
||||
<p class="error_message hidden"></p>
|
||||
</div>
|
||||
{% endfor %}
|
||||
|
||||
{% if not specific_filter %}
|
||||
<div id="filter_new" class="filter panel">
|
||||
<h2 class="name_header">New filter</h2>
|
||||
<input id="add_filter_name_input" type="text" class="set_name_input" placeholder="Name" data-bind-enter-to-button="add_filter_button" spellcheck="false"/>
|
||||
|
||||
<br/>
|
||||
|
||||
<textarea id="add_filter_conditions_input" class="set_conditions_input" data-bind-ctrl-enter-to-button="add_filter_button" placeholder="Conditions" spellcheck="false"></textarea>
|
||||
|
||||
<textarea id="add_filter_actions_input" class="set_actions_input" data-bind-ctrl-enter-to-button="add_filter_button" placeholder="Actions" spellcheck="false"></textarea>
|
||||
|
||||
<br/>
|
||||
|
||||
<button id="add_filter_button" class="button_with_spinner" data-spinner-text="⌛" onclick="return add_filter_form(event);">Add filter</button>
|
||||
|
||||
<p class="error_message hidden"></p>
|
||||
</div>
|
||||
{% endif %}
|
||||
</div>
|
||||
|
||||
<div id="right" class="panel">
|
||||
<h1>Filters</h1>
|
||||
<p>Every filter has a condition expression and a list of actions. The actions will take place if the entire condition expression evaluates to True.</p>
|
||||
|
||||
<p>When a news item arrives in the database, the filters that belong to its feed will run in order of priority. Then, any filters from the parent feed will run. If the news gets moved to a different feed, the filters belonging to that feed will run, and so forth until all of the filters finish running or the action <code>then_stop_filters</code> is used.</p>
|
||||
|
||||
<p>Some conditions and actions accept an argument. Use a colon <code>:</code> to separate the command name from the argument.</p>
|
||||
|
||||
<h2>Conditions</h2>
|
||||
<p>Combine the following functions to create a boolean expression. You can use logical operators AND, OR, NOT, XOR, as well as grouping parentheses to create complex expressions.</p>
|
||||
<b>Conditions with no arguments:</b>
|
||||
<ul>
|
||||
{% for name in filter_class._function_list('condition', 0) %}
|
||||
<li><code>{{name}}</code></li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
|
||||
<b>Conditions with 1 argument:</b>
|
||||
<ul>
|
||||
{% for name in filter_class._function_list('condition', 1) %}
|
||||
<li><code>{{name}}</code></li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
|
||||
<p>Note: If your argument contains spaces or parentheses, place quotation marks around the entire condition:argument so the parser doesn't them get confused with grouping. E.g. <code>"title_regex:free stuff"</code>, <code>"title_regex:(gog)"</code></p>
|
||||
|
||||
<p>Note: When using regular expressions, you'll have to double up your backslashes. One backslash escapes the expression parser, and the other backslash goes to your regular expression. E.g. <code>\\d</code>, <code>example\\.com</code>. Sorry for the inconvenience.</p>
|
||||
|
||||
<h2>Actions</h2>
|
||||
<p>Each line of this field represents a single action. If the condition evaluates to True, then all of your actions will execute in order. You can not choose to execute only some of the actions — for that, create a separate filter.</p>
|
||||
<p>You must place either <code>then_continue_filters</code> or <code>then_stop_filters</code> as the final action, and these must not appear anywhere except the final position.</p>
|
||||
|
||||
<b>Actions with no arguments:</b>
|
||||
<ul>
|
||||
{% for name in filter_class._function_list('action', 0) %}
|
||||
<li><code>{{name}}</code></li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
|
||||
<b>Actions with 1 argument:</b>
|
||||
<ul>
|
||||
{% for name in filter_class._function_list('action', 1) %}
|
||||
<li><code>{{name}}</code></li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
|
||||
<p>The <code>send_to_py</code> action allows you to run your own Python file with a news object. Your python file must define a function called <code>main</code> that only takes one argument, the news object, and returns the integer 0 if everything goes okay. If your function does not return 0, the action will fail. See <code>bringrss/objects.py</code> to see the News class.</p>
|
||||
|
||||
<h2>Examples</h2>
|
||||
|
||||
<pre>
|
||||
Conditions:
|
||||
always
|
||||
|
||||
Actions:
|
||||
set_read:yes
|
||||
then_stop_filters
|
||||
</pre>
|
||||
|
||||
<pre>
|
||||
Conditions:
|
||||
enclosure_regex:\\.mp3$ AND NOT (is_read OR is_recycled)
|
||||
|
||||
Actions:
|
||||
send_to_py:D:\bringrss\myscripts\download_podcast.py
|
||||
set_read:yes
|
||||
then_continue_filters
|
||||
</pre>
|
||||
|
||||
<pre>
|
||||
Conditions:
|
||||
anywhere_regex:politics
|
||||
|
||||
Actions:
|
||||
set_recycled:yes
|
||||
then_stop_filters
|
||||
</pre>
|
||||
|
||||
<pre>
|
||||
Conditions:
|
||||
(anywhere_regex:github\\.com/voussoir OR anywhere_regex:voussoir\\.net)
|
||||
AND NOT (is_read OR is_recycled)
|
||||
|
||||
Actions:
|
||||
move_to_feed:0123456789
|
||||
send_to_py:D:\bringrss\myscripts\username_mention.py
|
||||
then_continue_filters
|
||||
</pre>
|
||||
</div>
|
||||
</div>
|
||||
</body>
|
||||
|
||||
<script type="text/javascript">
|
||||
{% if specific_filter %}
|
||||
const SPECIFIC_FILTER = {{specific_filter}};
|
||||
{% else %}
|
||||
const SPECIFIC_FILTER = null;
|
||||
{% endif %}
|
||||
|
||||
function add_filter_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
spinners.close_button_spinner(button);
|
||||
if (! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
if (response.data.type === "error")
|
||||
{
|
||||
show_error_message(filter, `${response.data.error_type}: ${response.data.error_message}`);
|
||||
return;
|
||||
}
|
||||
if (response.meta.status != 200)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
common.refresh();
|
||||
}
|
||||
const button = event.target;
|
||||
const filter = button.closest(".filter");
|
||||
clear_error_message(filter);
|
||||
|
||||
const name = document.getElementById("add_filter_name_input").value.trim();
|
||||
const conditions = document.getElementById("add_filter_conditions_input").value.trim();
|
||||
const actions = document.getElementById("add_filter_actions_input").value.trim();
|
||||
|
||||
if ((! conditions) || (! actions))
|
||||
{
|
||||
return spinners.BAIL;
|
||||
}
|
||||
|
||||
api.filters.add_filter(name, conditions, actions, callback);
|
||||
}
|
||||
|
||||
function clear_error_message(filter)
|
||||
{
|
||||
const p = filter.getElementsByClassName("error_message")[0];
|
||||
p.innerText = "";
|
||||
p.classList.add("hidden");
|
||||
}
|
||||
|
||||
function delete_filter_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
if (! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
if (response.data.type === "error")
|
||||
{
|
||||
show_error_message(filter, `${response.data.error_type}: ${response.data.error_message}`);
|
||||
return;
|
||||
}
|
||||
if (response.meta.status != 200)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
if (SPECIFIC_FILTER)
|
||||
{
|
||||
window.location.href = "/filters";
|
||||
}
|
||||
else
|
||||
{
|
||||
filter.parentElement.removeChild(filter);
|
||||
}
|
||||
}
|
||||
const button = event.target;
|
||||
const filter = button.closest(".filter");
|
||||
clear_error_message(filter);
|
||||
|
||||
const filter_id = filter.dataset.id;
|
||||
api.filters.delete_filter(filter_id, callback);
|
||||
}
|
||||
|
||||
function show_error_message(filter, message)
|
||||
{
|
||||
const p = filter.getElementsByClassName("error_message")[0];
|
||||
p.innerText = message;
|
||||
p.classList.remove("hidden");
|
||||
}
|
||||
|
||||
function update_filter_form(event)
|
||||
{
|
||||
function callback(response)
|
||||
{
|
||||
spinners.close_button_spinner(button);
|
||||
if (! response.meta.json_ok)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
if (response.data.type === "error")
|
||||
{
|
||||
show_error_message(filter, `${response.data.error_type}: ${response.data.error_message}`);
|
||||
return;
|
||||
}
|
||||
if (response.meta.status != 200)
|
||||
{
|
||||
alert(JSON.stringify(response));
|
||||
return;
|
||||
}
|
||||
|
||||
// Don't overwrite the box if the user has since changed their mind and
|
||||
// typed something else.
|
||||
if (name_input.value === name)
|
||||
{
|
||||
name_input.value = response.data.name;
|
||||
}
|
||||
if (conditions_input.value === conditions)
|
||||
{
|
||||
conditions_input.value = response.data.conditions;
|
||||
}
|
||||
if (actions_input.value === actions)
|
||||
{
|
||||
actions_input.value = response.data.actions;
|
||||
}
|
||||
}
|
||||
const button = event.target;
|
||||
const filter = button.closest(".filter");
|
||||
clear_error_message(filter);
|
||||
|
||||
const name_input = filter.querySelector(".set_name_input");
|
||||
const conditions_input = filter.querySelector(".set_conditions_input");
|
||||
const actions_input = filter.querySelector(".set_actions_input");
|
||||
|
||||
name_input.value = name_input.value.trim();
|
||||
conditions_input.value = conditions_input.value.trim();
|
||||
actions_input.value = actions_input.value.trim();
|
||||
|
||||
name = name_input.value;
|
||||
conditions = conditions_input.value;
|
||||
actions = actions_input.value;
|
||||
|
||||
if ((! conditions) || (! actions))
|
||||
{
|
||||
return spinners.BAIL;
|
||||
}
|
||||
|
||||
api.filters.update_filter(filter.dataset.id, name, conditions, actions, callback);
|
||||
}
|
||||
|
||||
function on_pageload()
|
||||
{
|
||||
}
|
||||
document.addEventListener("DOMContentLoaded", on_pageload);
|
||||
</script>
|
||||
</html>
|
||||
10
frontends/bringrss_flask/templates/header.html
Normal file
10
frontends/bringrss_flask/templates/header.html
Normal file
|
|
@ -0,0 +1,10 @@
|
|||
{% macro make_header(site, request) %}
|
||||
<nav id="header">
|
||||
<a class="header_element" href="/">BringRSS</a>
|
||||
<a class="header_element" href="/filters">Filters</a>
|
||||
<a class="header_element" href="/about">About</a>
|
||||
{% if site.demo_mode %}
|
||||
<span class="demo_mode_alert" title="The site is in demo mode. No changes you make will be saved.">(demo mode)</span>
|
||||
{% endif %}
|
||||
</nav>
|
||||
{% endmacro %}
|
||||
2044
frontends/bringrss_flask/templates/root.html
Normal file
2044
frontends/bringrss_flask/templates/root.html
Normal file
File diff suppressed because it is too large
Load diff
48
frontends/bringrss_repl.py
Normal file
48
frontends/bringrss_repl.py
Normal file
|
|
@ -0,0 +1,48 @@
|
|||
import argparse
|
||||
import code
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
from voussoirkit import interactive
|
||||
from voussoirkit import pipeable
|
||||
from voussoirkit import vlogging
|
||||
|
||||
import bringrss
|
||||
|
||||
def bringrepl_argparse(args):
|
||||
global B
|
||||
|
||||
try:
|
||||
B = bringrss.bringdb.BringDB.closest_bringdb()
|
||||
except bringrss.exceptions.NoClosestBringDB as exc:
|
||||
pipeable.stderr(exc.error_message)
|
||||
pipeable.stderr('Try `bringrss_cli.py init` to create the database.')
|
||||
return 1
|
||||
|
||||
if args.exec_statement:
|
||||
exec(args.exec_statement)
|
||||
B.commit()
|
||||
else:
|
||||
while True:
|
||||
try:
|
||||
code.interact(banner='', local=dict(globals(), **locals()))
|
||||
except SystemExit:
|
||||
pass
|
||||
if len(B.savepoints) == 0:
|
||||
break
|
||||
print('You have uncommited changes, are you sure you want to quit?')
|
||||
if interactive.getpermission():
|
||||
break
|
||||
|
||||
@vlogging.main_decorator
|
||||
def main(argv):
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument('--exec', dest='exec_statement', default=None)
|
||||
parser.set_defaults(func=bringrepl_argparse)
|
||||
|
||||
args = parser.parse_args(argv)
|
||||
return args.func(args)
|
||||
|
||||
if __name__ == '__main__':
|
||||
raise SystemExit(main(sys.argv[1:]))
|
||||
2619
reference/atom_spec.html
Normal file
2619
reference/atom_spec.html
Normal file
File diff suppressed because it is too large
Load diff
1311
reference/rss_spec.html
Normal file
1311
reference/rss_spec.html
Normal file
File diff suppressed because it is too large
Load diff
19
requirements.txt
Normal file
19
requirements.txt
Normal file
|
|
@ -0,0 +1,19 @@
|
|||
# For fetching feeds
|
||||
requests
|
||||
|
||||
# For parsing RSS and Atom XML
|
||||
bs4
|
||||
|
||||
# For parsing RSS published times
|
||||
python-dateutil
|
||||
|
||||
# For running the webserver
|
||||
flask
|
||||
gevent
|
||||
werkzeug
|
||||
|
||||
# For normalizing feed icons to 32x32 png
|
||||
pillow
|
||||
|
||||
# My own variety toolkit
|
||||
voussoirkit
|
||||
196
utilities/import_quiterss.py
Normal file
196
utilities/import_quiterss.py
Normal file
|
|
@ -0,0 +1,196 @@
|
|||
import base64
|
||||
import argparse
|
||||
import os
|
||||
import sqlite3
|
||||
import textwrap
|
||||
import sys
|
||||
|
||||
from voussoirkit import betterhelp
|
||||
from voussoirkit import pipeable
|
||||
from voussoirkit import vlogging
|
||||
from voussoirkit import interactive
|
||||
from voussoirkit import niceprints
|
||||
|
||||
import bringrss
|
||||
|
||||
log = vlogging.getLogger(__name__, 'import_quiterss')
|
||||
|
||||
def import_quiterss_argparse(args):
|
||||
bringdb = bringrss.bringdb.BringDB.closest_bringdb()
|
||||
if not os.path.isfile(args.feedsdb):
|
||||
pipeable.stderr(f'{args.bringdb} is not a file.')
|
||||
return 1
|
||||
|
||||
message = textwrap.dedent('''
|
||||
You should make a backup of your BringRSS database before doing this.
|
||||
Do not perform this import more than once. We will not search for duplicate data.
|
||||
If you need to try the import again, restore from your backup first.
|
||||
|
||||
Only feeds and news are imported. Filters are not. Sorry for the inconvenience.
|
||||
''').strip()
|
||||
|
||||
pipeable.stderr()
|
||||
pipeable.stderr(niceprints.in_box(message, title='Importing from QuiteRSS'))
|
||||
|
||||
if not interactive.getpermission('Are you ready?'):
|
||||
return 1
|
||||
|
||||
quite_sql = sqlite3.connect(args.feedsdb)
|
||||
quite_sql.row_factory = sqlite3.Row
|
||||
feed_id_map = {}
|
||||
query = '''
|
||||
SELECT
|
||||
id,
|
||||
text,
|
||||
description,
|
||||
xmlUrl,
|
||||
htmlUrl,
|
||||
image,
|
||||
parentId,
|
||||
rowToParent,
|
||||
updateIntervalEnable,
|
||||
updateInterval,
|
||||
updateIntervalType,
|
||||
disableUpdate
|
||||
FROM feeds;
|
||||
'''
|
||||
feeds = list(quite_sql.execute(query))
|
||||
while feeds:
|
||||
feed = feeds.pop(0)
|
||||
quite_id = feed['id']
|
||||
if feed['parentId'] == 0:
|
||||
parent = None
|
||||
elif feed['parentId'] in feed_id_map:
|
||||
parent = feed_id_map[feed['parentId']]
|
||||
else:
|
||||
# The parent is probably somewhere else in the list, let's come
|
||||
# back to it later.
|
||||
feeds.append(feed)
|
||||
continue
|
||||
|
||||
title = feed['text']
|
||||
description = feed['description']
|
||||
rss_url = feed['xmlUrl']
|
||||
web_url = feed['htmlUrl']
|
||||
# rowToParent is zero-indexed, we use 1-index.
|
||||
if parent:
|
||||
# If the parent has ui_order_rank of 8, then a child with rowToParent
|
||||
# of 4 will be 8.0004 and everything will get reassigned later.
|
||||
ui_order_rank = parent.ui_order_rank + ((feed['rowToParent'] + 1) / 10000)
|
||||
else:
|
||||
ui_order_rank = feed['rowToParent'] + 1
|
||||
|
||||
if feed['updateIntervalEnable'] == 1 and feed['updateInterval'] > 0:
|
||||
if feed['updateIntervalType'] in {1, "1"}:
|
||||
# hours
|
||||
autorefresh_interval = feed['updateInterval'] * 3600
|
||||
elif feed['updateIntervalType'] in {0, "0"}:
|
||||
# minutes
|
||||
autorefresh_interval = feed['updateInterval'] * 60
|
||||
elif feed['updateIntervalType'] in {-1, "-1"}:
|
||||
# seconds
|
||||
autorefresh_interval = feed['updateInterval']
|
||||
else:
|
||||
autorefresh_interval = 0
|
||||
|
||||
if feed['disableUpdate'] == 1:
|
||||
refresh_with_others = False
|
||||
autorefresh_interval = min(autorefresh_interval, -1 * autorefresh_interval)
|
||||
else:
|
||||
refresh_with_others = True
|
||||
|
||||
isolate_guids = False
|
||||
|
||||
if feed['image']:
|
||||
icon = base64.b64decode(feed['image'])
|
||||
else:
|
||||
icon = None
|
||||
|
||||
feed = bringdb.add_feed(
|
||||
autorefresh_interval=autorefresh_interval,
|
||||
description=description,
|
||||
icon=icon,
|
||||
isolate_guids=isolate_guids,
|
||||
parent=parent,
|
||||
refresh_with_others=refresh_with_others,
|
||||
rss_url=rss_url,
|
||||
title=title,
|
||||
ui_order_rank=ui_order_rank,
|
||||
web_url=web_url,
|
||||
)
|
||||
feed_id_map[quite_id] = feed
|
||||
|
||||
bringdb.reassign_ui_order_ranks()
|
||||
|
||||
query = '''
|
||||
SELECT
|
||||
feedId,
|
||||
guid,
|
||||
description,
|
||||
title,
|
||||
published,
|
||||
modified,
|
||||
author_name,
|
||||
author_uri,
|
||||
author_email,
|
||||
read,
|
||||
comments,
|
||||
enclosure_length,
|
||||
enclosure_type,
|
||||
enclosure_url,
|
||||
link_href
|
||||
FROM news
|
||||
WHERE deleted == 0;
|
||||
'''
|
||||
newss = list(quite_sql.execute(query))
|
||||
for news in newss:
|
||||
quite_read = news['read']
|
||||
|
||||
authors = [{
|
||||
'name': news['author_name'],
|
||||
'email': news['author_email'],
|
||||
'uri': news['author_uri'],
|
||||
}]
|
||||
enclosures = [{
|
||||
'url': news['enclosure_url'],
|
||||
'type': news['enclosure_type'],
|
||||
'size': int(news['enclosure_length']) if news.get('enclosure_length') else None
|
||||
}]
|
||||
|
||||
news = bringdb.add_news(
|
||||
authors=authors,
|
||||
comments_url=news['comments'],
|
||||
enclosures=enclosures,
|
||||
feed=feed_id_map[news['feedId']],
|
||||
published=news['published'],
|
||||
rss_guid=news['guid'],
|
||||
text=news['description'],
|
||||
title=news['title'],
|
||||
updated=news['modified'] or news['published'],
|
||||
web_url=news['link_href'],
|
||||
)
|
||||
if quite_read > 0:
|
||||
news.set_read(True)
|
||||
bringdb.commit()
|
||||
|
||||
return 0
|
||||
|
||||
@vlogging.main_decorator
|
||||
def main(argv):
|
||||
parser = argparse.ArgumentParser(
|
||||
description='''
|
||||
Import feeds and news from QuiteRSS to BringRSS.
|
||||
''',
|
||||
)
|
||||
parser.add_argument(
|
||||
'feedsdb',
|
||||
help='''
|
||||
Filepath to the feeds.db in your QuiteRSS folder.
|
||||
''',
|
||||
)
|
||||
parser.set_defaults(func=import_quiterss_argparse)
|
||||
|
||||
return betterhelp.go(parser, argv)
|
||||
|
||||
if __name__ == '__main__':
|
||||
raise SystemExit(main(sys.argv[1:]))
|
||||
Loading…
Reference in a new issue