| bringrss | ||
| frontends | ||
| reference | ||
| utilities | ||
| .gitignore | ||
| bringrss_logo.svg | ||
| CONTACT.md | ||
| LICENSE.txt | ||
| README.md | ||
| requirements.txt | ||
{kind=link}
BringRSS
It brings you the news.
Live demo: https://bringrss.voussoir.net
What am I looking at
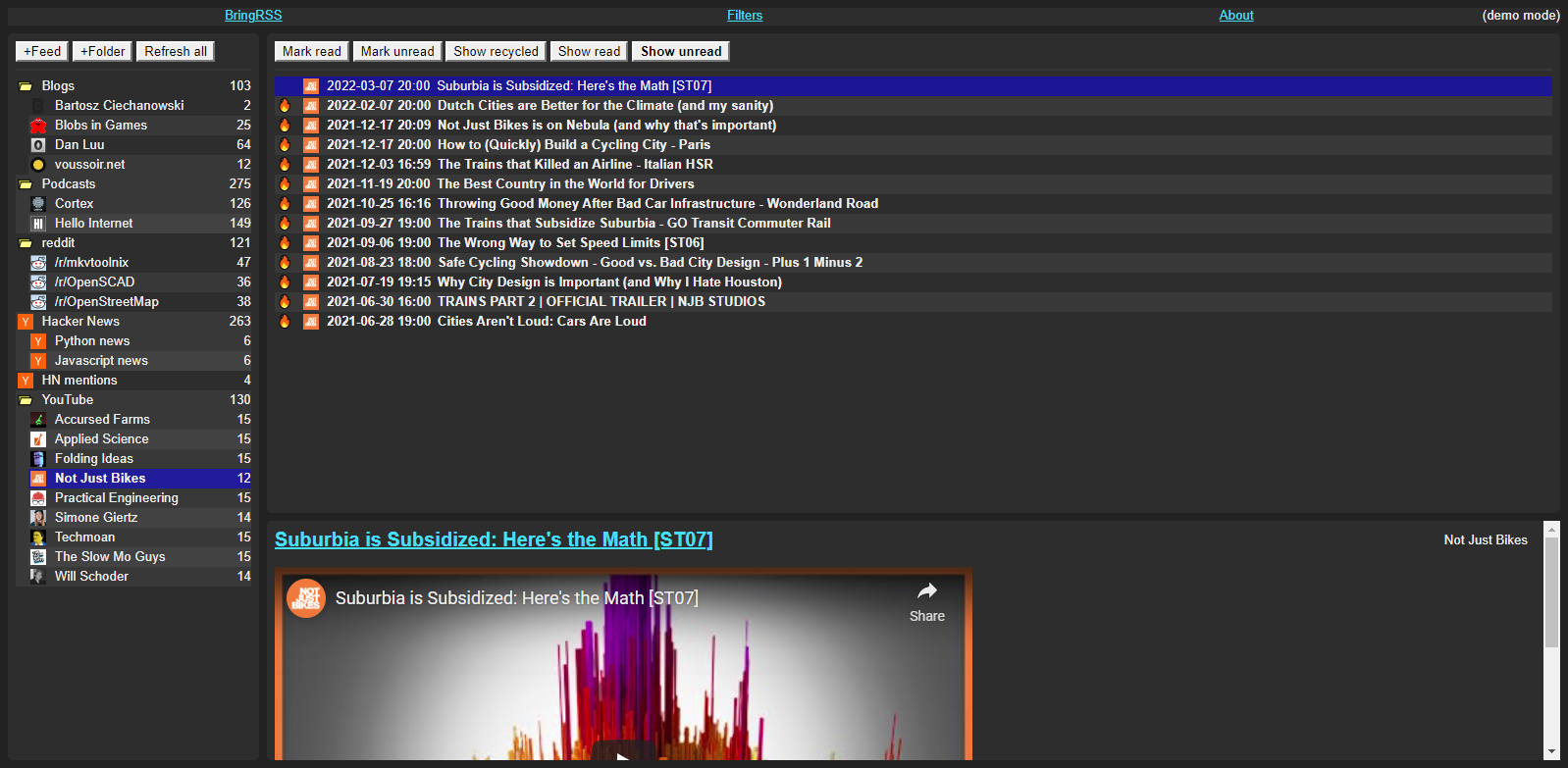
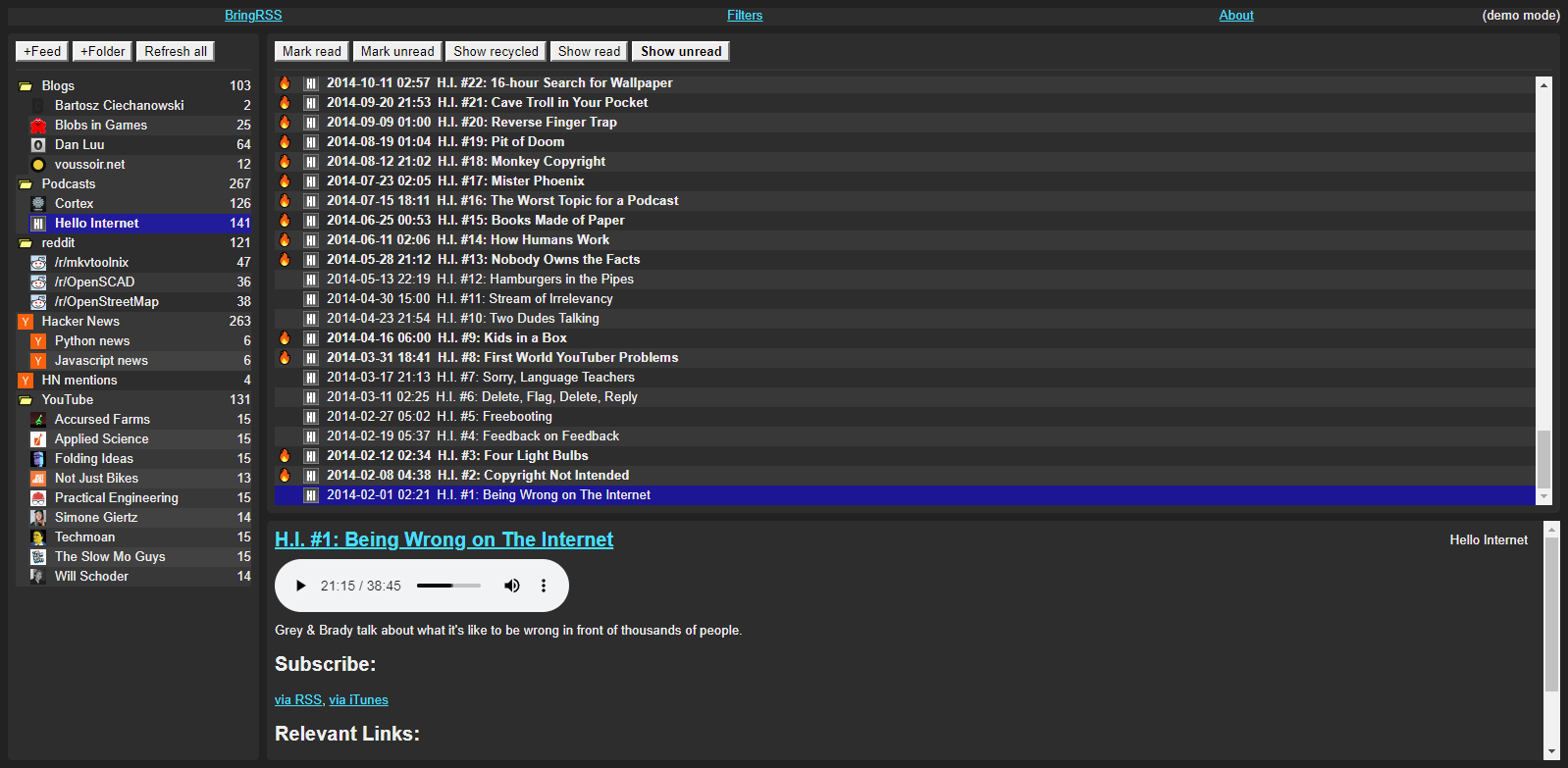
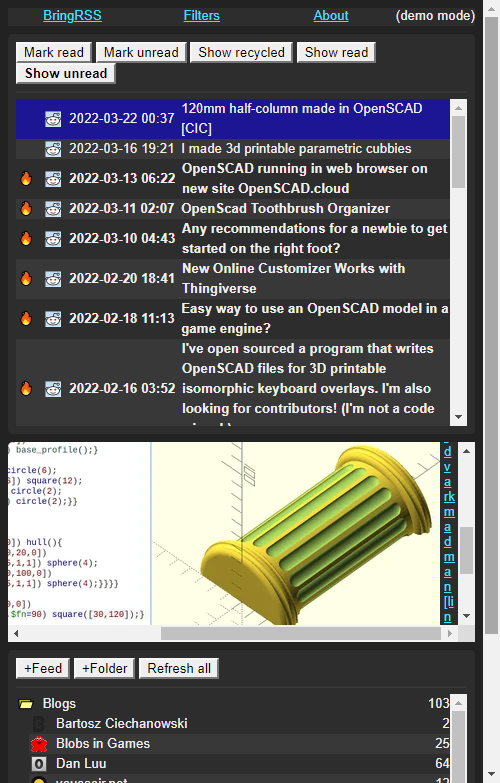
BringRSS is an RSS client / newsreader made with Python, SQLite3, and Flask. Its main features are:
- Automatic feed refresh with separate intervals per feed.
- Feeds arranged in hierarchical folders.
- Filters for categorizing or removing news based on your criteria.
- Sends news objects to your own Python scripts for arbitrary post-processing, emailing, downloading, etc.
- Embeds videos from YouTube feeds.
- News text is filtered by DOMPurify before display.
- Supports multiple enclosures.
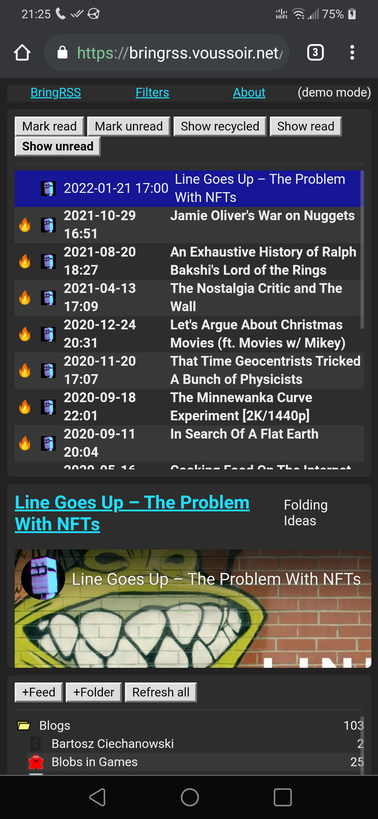
Because BringRSS runs a webserver, you can access it from every device in your house via your computer's LAN IP. BringRSS provides no login or authentication, but if you have a reverse proxy handle that for you, you could run BringRSS on an internet-connected machine and access your feeds anywhere.
Screenshots



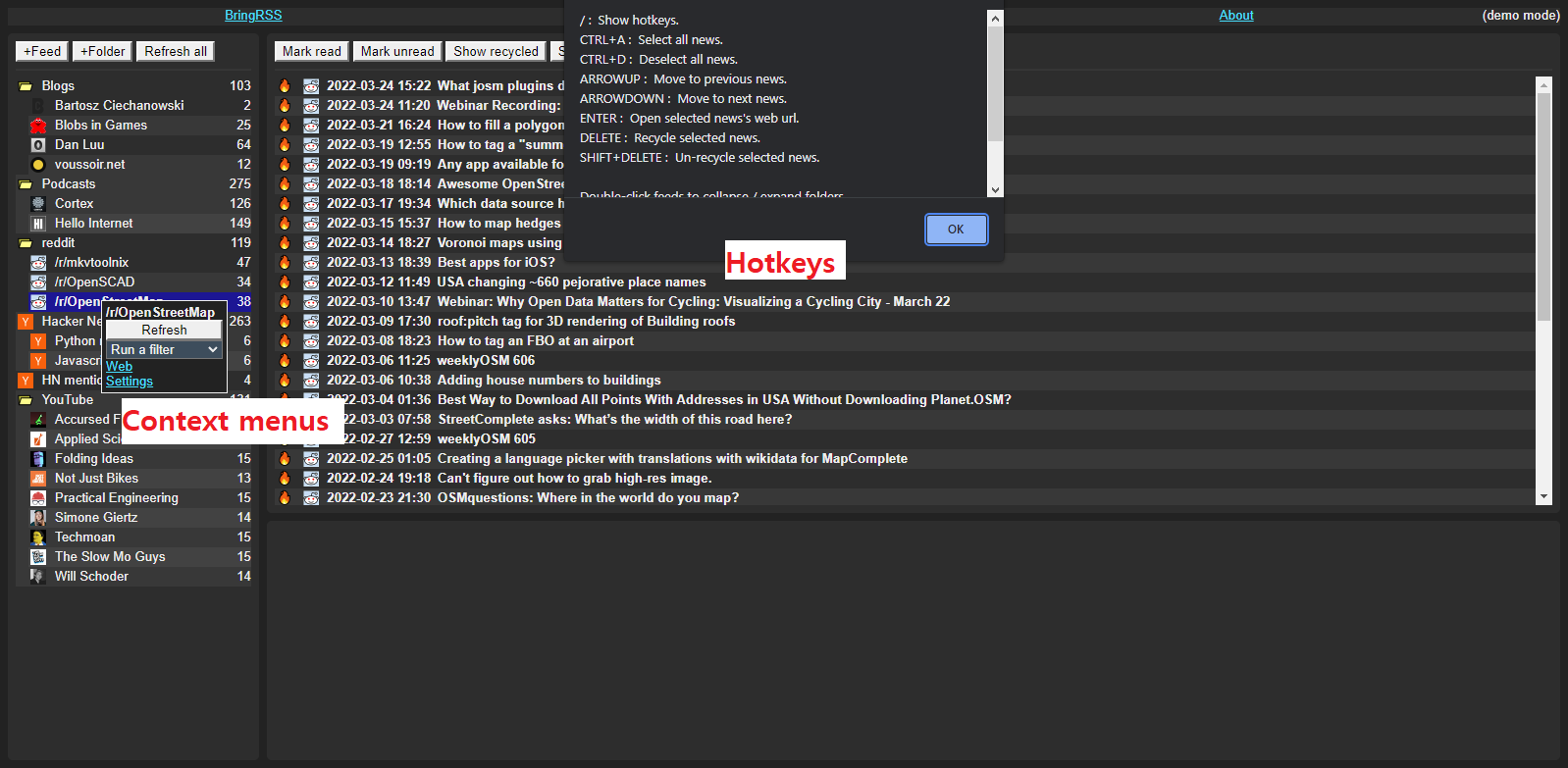
Setting up
As you'll see below, BringRSS has a core backend package and separate frontends that use it. These frontend applications will use import bringrss to access the backend code. Therefore, the bringrss package needs to be in the right place for Python to find it for import.
-
Run
pip install -r requirements.txt --upgradeafter reading the file and deciding you are ok with the dependencies. -
Make a new folder somewhere on your computer, and add this folder to your
PYTHONPATHenvironment variable. For example, I might useD:\pythonpathor~/pythonpath. Close and re-open your Command Prompt / Terminal so it reloads the environment variables. -
Add a symlink to the bringrss folder into that folder:
The repository you are looking at now is
D:\Git\BringRSSor~/Git/BringRSS. You can see the folder calledbringrss.Windows:
mklink /d fakepath realpath
for examplemklink /d "D:\pythonpath\bringrss" "D:\Git\BringRSS\bringrss"Linux:
ln --symbolic realpath fakepath
for exampleln --symbolic "~/Git/BringRSS/bringrss" "~/pythonpath/bringrss" -
Run
python -c "import bringrss; print(bringrss)". You should see the module print successfully.
Running BringRSS CLI
BringRSS offers a commandline interface so you can use cronjobs to refresh your feeds. More commands may be added in the future.
-
cdto the folder where you'd like to create the BringRSS database. -
Run
python frontends/bringrss_cli.py --helpto learn about the available commands. -
Run
python frontends/bringrss_cli.py initto create a database in the current directory.
Note: Do not cd into the frontends folder. Stay in the folder that contains your _bringrss database and specify the full path of the frontend launcher. For example:
Windows:
D:\somewhere> python D:\Git\BringRSS\frontends\bringrss_cli.py
Linux:
/somewhere $ python /Git/BringRSS/frontends/bringrss_cli.py
It is expected that you create a shortcut file or launch script so you don't have to type the whole filepath every time. For example, I have a bringcli.lnk on my PATH with target=D:\Git\BringRSS\frontends\bringrss_cli.py.
Running BringRSS Flask locally
-
Run
python frontends/bringrss_flask/bringrss_flask_dev.py --helpto learn the available options. -
Run
python frontends/bringrss_flask/bringrss_flask_dev.py [port]to launch the flask server. If this is your first time running it, you can add--initto create a new database in the current directory. Port defaults to 27464 if not provided. -
Open your web browser to
localhost:<port>.
Note: Do not cd into the frontends folder. Stay in the folder that contains your _bringrss database and specify the full path of the frontend launcher. For example:
Windows:
D:\somewhere> python D:\Git\BringRSS\frontends\bringrss_flask\bringrss_flask_dev.py 5001
Linux:
/somewhere $ python /Git/BringRSS/frontends/bringrss_flask/bringrss_flask_dev.py 5001
Add --help to learn the arguments.
It is expected that you create a shortcut file or launch script so you don't have to type the whole filepath every time. For example, I have a bringflask.lnk on my PATH with target=D:\Git\BringRSS\frontends\bringrss_flask\bringrss_flask_dev.py.
Running BringRSS Flask with Gunicorn
BringRSS provides no authentication whatsoever, so you probably shouldn't deploy it publicly unless your proxy server does authentication for you. However, I will tell you that for the purposes of running the demo site, I am using a script like this:
export BRINGRSS_DEMO_MODE=1
~/cmd/python ~/cmd/gunicorn_py bringrss_flask_prod:site --bind "0.0.0.0:PORTNUMBER" --worker-class gevent --access-logfile "-" --access-logformat "%(h)s | %(t)s | %(r)s | %(s)s %(b)s"
Running BringRSS REPL
The REPL is a great way to test a quick idea and learn the data model.
-
Use
bringrss_cli initto create the database in the desired directory. -
Run
python frontends/bringrss_repl.pyto launch the Python interpreter with the BringDB pre-loaded into a variable calledB. Try things likeB.get_feedorB.get_newss.
Note: Do not cd into the frontends folder. Stay in the folder that contains your _bringrss database and specify the full path of the frontend launcher. For example:
Windows:
D:\somewhere> python D:\Git\BringRSS\frontends\bringrss_repl.py
Linux:
/somewhere $ python /Git/BringRSS/frontends/bringrss_repl.py
It is expected that you create a shortcut file or launch script so you don't have to type the whole filepath every time. For example, I have a bringrepl.lnk on my PATH with target=D:\Git\BringRSS\frontends\bringrss_repl.py.
Help wanted: javascript perf & layout thrashing
I think there is room for improvement in root.html's javascript. When reading a feed with a few thousand news items, the UI starts to get slow at every interaction:
- After clicking on a news, it takes a few ms before it turns selected.
- The newsreader takes a few ms to populate with the title even though it's pulled from the news's DOM, not the network.
- After receiving the news list from the server, news are inserted into the dom in batches, and each batch causes the UI to stutter if you are also trying to scroll or click on things.
If you have any tips for improving the performance and responsiveness of the UI click handlers and reducing the amount of reflow / layout caused by the loading of news items or changing their class (selecting, reading, recycling), I would appreciate you getting in touch at contact@voussoir.net or opening an issue. Please don't open a pull request without talking to me first.
I am aware of virtual scrolling techniques where DOM rows don't actually exist until you scroll to where they would be, but this has the drawback of breaking ctrl+f and also it is hard to precompute the scroll height since news have variable length titles. I would prefer simple fixes like adding CSS rules that help the layout engine make better reflow decisions.
To do list
- Maybe we could add a very basic password system to facilitate running an internet-connected instance. No user profiles, just a single password to access the whole system. I did this with simpleserver.
- "Fill in the gaps" feature. Many websites have feeds that don't reach back all the way to their first post. When discovering a new blog or podcast, catching up on their prior work requires manual bookmarking outside of your newsreader. It would be nice to dump a list of article URLs into BringRSS and have it generate news objects as if they really came from the feed. Basic information like url, title, and fetched page text would be good enough; auto-detecting media as enclosures would be better. Other attributes don't need to be comprehensive. Then you could have everything in your newsreader.
Mirrors
https://github.com/voussoir/bringrss